
はじめに
基礎技術研究室リサーチエンジニアの中川です。 先日行われた CODE BLUE 2021 に参加し、登壇してきました。
今回の記事では本研究をスタートして CFP に応募し、採択に至るまでの経緯について紹介していきます。
- はじめに
- 今年の CODE BLUE
- 研究の背景と概要
- 研究のきっかけ
- %SystemRoot%\System32 以下のシステム DLL の調査
- 新しい再配置エントリーの発見
- IMAGE_DYNAMIC_RELOCATION_ARM64X の悪用による難読化手法について
- Hybrid Auxiliary IAT の発見と Microsoft による ARM64EC の発表
- CODE BLUE CFP への応募と採択
- おわりに
- 謝辞
今年の CODE BLUE
まず CODE BLUE について簡単に説明します。
CODE BLUE は日本発の情報セキュリティの国際会議です。 ここでは世界トップレベルの研究者による講演、国や言語の垣根を超えた交流や情報交換の場が提供されています。
今年は新型コロナの影響もあり、ハイブリッド (オンサイトとオンライン) での開催となりました。 発表形式としてはオンサイトでの発表・レコード済みのビデオを流すことによる発表・Zoom を使った発表の 3 種類がありました。 私はオンサイトでの発表を選択しました。
研究の背景と概要
研究を開始し採択に至るまでの経緯を説明する前に、今回発表した研究の背景について説明します。
近年、ARM *1 プロセッサはスマートフォンやタブレットに限らず、ノート PC においても使われる事例が増えてきました。 例えば、ARM 版 Windows を搭載した Surface Pro X、昨年発売され大きな話題を呼んだ M1 Mac などが挙げられます。
ARM 版 Windows は 2017 年 12 月に発表され、翌年には搭載端末が発売されています。 このように Microsoft による取り組み自体は早い段階から行われています。 発表当初は端末自体が限られていましたが、近年では徐々に数を増やしつつあります。 フラグシップモデルである Surface でも採用されるなど、Microsoft も力を入れて取り組んでいることが伺えます。
こうした ARM ベースのノート PC ですが、やはり電力辺りの性能が優れている点が特徴です。 中には 4G LTE をサポートし、20 時間ほどバッテリー駆動出来るなど、スマートフォンのようにノート PC を使うことができる製品もあります。 時間や場所にとらわれない働き方をする方にとっては、非常に魅力的な端末と言えます。
一方で、既存のデバイスからこうした ARM ベースのノート PC への移行において問題になることとして、アプリケーションの互換性の問題があります。 これに関しては x86 から x64 の移行期では CPU モードの切り替えで x86 のコードを x64 上で実行できたため問題になりませんでした。 しかしながら、x86/x64 から ARM の場合だと当然ながらそのようなことはできません。
アプリケーションの互換性の問題の解決策として、ARM 版 Windows では様々な互換性テクノロジーが提供されています。 これには JIT で x86/x64 の命令列を ARM64 *2 に変換する XTAJIT や一度変換した結果をファイルとしてキャッシュする XtaCache などが挙げられます。 変換した結果が保存されているファイルは XTA Cache File と呼ばれます。 その他、CHPE や ARM64EC などのハイブリッドバイナリといった新しい技術も近年では導入されています。
さて、近年こうした互換性テクノロジーが複数提供されているわけですが、果たして攻撃者によって悪用される危険性はないでしょうか。 CODE BLUE 2021 ではこの点を明らかにする研究について発表しました。 研究の詳細については以下のスライドや研究成果をまとめたリポジトリをご参照ください。
www.slideshare.net
次にこの研究を始めるに至ったきっかけの部分を掘り下げて説明してきます。
研究のきっかけ
CODE BLUE で発表した研究は Black Hat EU 2020 で発表した内容がベースとなっています。
Black Hat EU 2020 では XTA Cache File を改ざんすることによるコードインジェクション手法について発表しました。
この発表の翌日に x64 エミュレーション機能が発表され、Insider 版の ARM 版 Windows 10 にて配信されました。 私は早速 ARM 版 Windows をアップデートし、x64 エミュレーション機能の実装がどのようになっているのかの調査を実施しました。
アップデートしてすぐに %SystemRoot%\System32 以下のシステム DLL のサイズがほぼ倍になっている点に気づきました (図 1)。
ここから x64 エミュレーションの導入に辺り、システムバイナリに大きな変化が加えられていることが容易に推測できました。

ntdll.dll のサイズの変化
x86 エミュレーションでは、次節で触れますが、CHPE と呼ばれる新しいバイナリが導入されていました。
もしかしたら x64 エミュレーション導入にあたっても、CHPE のように新しいタイプのバイナリが導入されたのではと考えました。
そのため、まず %SystemRoot%\System32 以下のシステム DLL から調査を開始することにしました。
%SystemRoot%\System32 以下のシステム DLL の調査
気になったためシステム DLL を Ghidra で開くと .hexpthk という名前のセクションが新しく追加されていることがわかりました (図 2)。
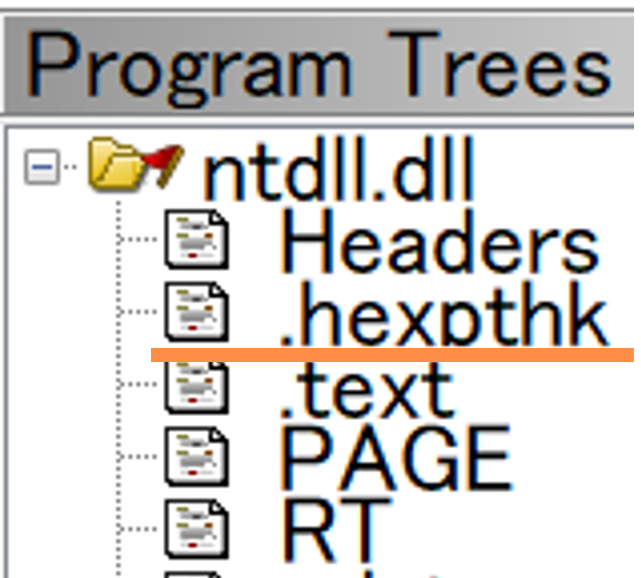
.hexpthk
.hexpthk *3 は CHPE に含まれる特徴的なセクションです。
ここで馴染みの無い方のために CHPE について少し補足して説明します。
CHPE は x86 PE との互換性を保ちつつ、ARM64 ネイティブとほぼ同等の速度でのコード実行を可能とするバイナリです。
x86 エミュレーションでは基本的にシステム DLL として CHPE のもの (%SystemRoot%\SyChpe32 ディレクトリに存在) が使われます。
x86 PE との互換性を保つため、例えば、file コマンドなどで表層情報を調べると x86 と表示されます。
また、export 関数を逆アセンブルした結果としては x86 の命令列が表示されます。
この export 関数は export thunk と呼ばれます。
この export thunk ですが、末尾が jmp 命令で終わっており、jmp 先には ARM64 コードが含まれていることがわかります (図 3)。 そして、ARM64 コードに関数の実装の本体が含まれています。
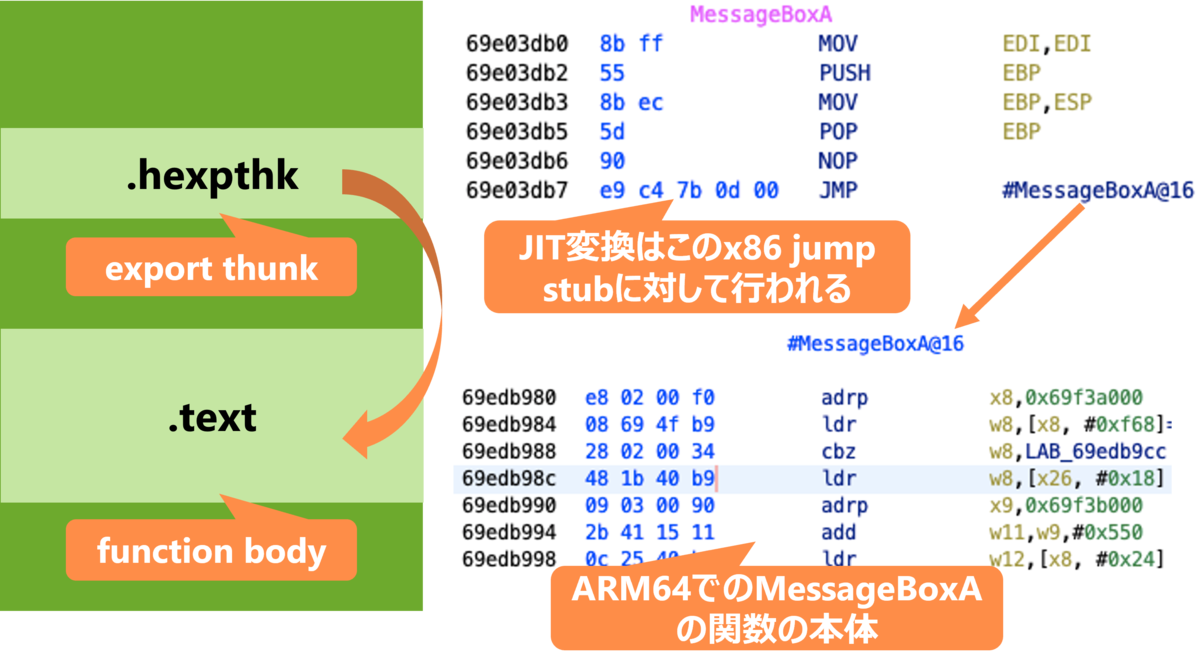
user32!MessageBoxA の場合の例)
このように x86 での export thunk と ARM64 の関数とを切り離した構成をしているため、実行にあたって JIT バイナリ変換は export thunk についてのみ行われます。 関数全体に対して JIT バイナリ変換する必要はありません。 そのため、実行自体は ARM64 ネイティブで実行した場合とほぼ同程度になります *4。
話を戻しましょう。
%SystemRoot%\System32 以下の DLL には .hexpthk というセクションが追加されていたのでした。
CHPE の場合は x86 PE との互換性を保っていたわけですから、x64 エミュレーション導入にあたり、x64 PE と互換性を保つように拡張されたバイナリが導入されたのではと推測しました。
しかし、file コマンドでバイナリの表層情報を調べてみると、ARM64 と表示されることがわかりました (図 4)。

%SystemRoot%\System32\ntdll.dll の表層情報
仮に CHPE が x64 向けに拡張されたのであれば、この結果は x64 と表示されるはずです。 したがって、単純に CHPE を x64 向けに拡張したものではないことがわかります。 (ちなみに、CHPE を x64 向けに拡張したものも存在することが後になってわかりました。こちらは ARM64EC と呼ばれています。)
また、この %SystemRoot%\System32 以下の DLL は表層情報が ARM64 であるにも関わらず、x64 エミュレーションプロセスからも問題なくロードされることがわかりました (図 5)。

DLL のアーキテクチャ情報と使うプロセスのアーキテクチャ情報は一致するのが通常です。
例えば、x86 プロセスから x64 の DLL をロードできません。
しかし、新しく導入された %SystemRoot%\System32 以下の DLL はこの規則を破っているように見えました。
その他、GetProcAddress 関数を呼び出して取得出来る export 関数のアドレスが、ARM64 ネイティブプロセスと x64 エミュレーションプロセスで異なる、という性質があることもわかりました。
例えば、以下のようなコードを考えます。
// LoadDll.c (ビルドした結果は LoadDll.exe として保存) #include <Windows.h> #include <stdio.h> int main() { HMODULE baseAddr = LoadLibraryA("user32.dll"); if (!baseAddr) { return EXIT_FAILURE; } printf("Image base address = %p\n", baseAddr); PVOID funcAddr = GetProcAddress(baseAddr, "MessageBoxA"); printf("MessageBoxA is located at %p\n", funcAddr); return EXIT_SUCCESS; }
これは、user32.dll をロードし、export されている MessageBoxA 関数の RVA を取得し、標準出力に表示するプログラムとなっています。
このプログラムを、ターゲットアーキテクチャを ARM64 と x64 にそれぞれ設定してビルドし実行すると以下のような結果が得られます (図 6)。
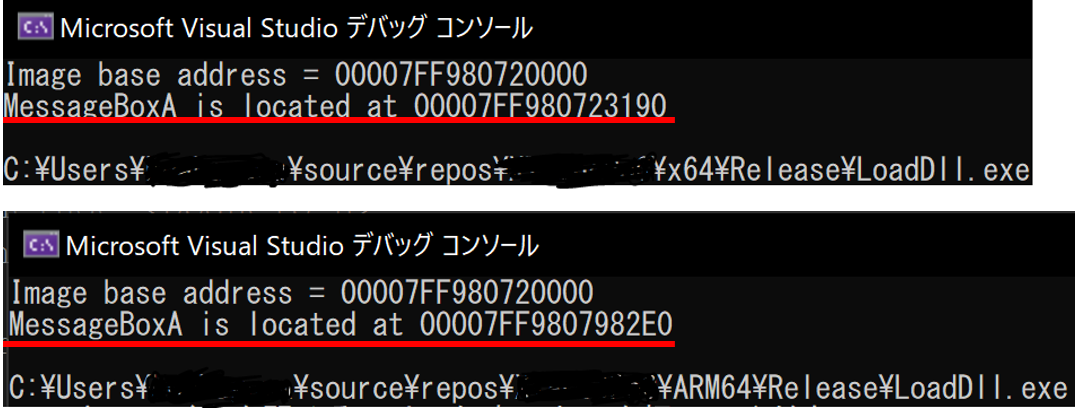
export されている MessageBoxA の関数のアドレスを見てみると、2 つの実行において異なる値になっていることがわかります。
(ここで user32.dll の image base の値は 2 つの実行において同じである点に注意してください。)
すなわち、x64 エミュレーションプロセスと ARM64 ネイティブプロセスが使う場合とで export される関数が異なっているのです。 さらに調べてみると、EAT への RVA が x64 エミュレーションプロセスが使うときのみ、実行時に上書きされ別の値になっていることがわかりました。
もしやと思い、ロードされた DLL の IMAGE_FILE_HEADER の Machine の値を調べると、x64 エミュレーションプロセスが使うときのみ ARM64 (0xaa64) から x64 (0x8664) に変化していることもわかりました。
そのため、x64 エミュレーションプロセスがこの DLL を使う場合、DLL のアーキテクチャ情報は x64 に変化し、使うプロセスのアーキテクチャ情報と不一致が起きないようになっていました。
これらの結果から x64 エミュレーションプロセスが使う時のみ、DLL に対して動的なパッチが施されていることがわかります。 私はこの時点で、既存の dynamic relocation の仕組みが拡張され、動的なパッチが施されるように変更されたのではないかと考えました。
ただ、その時は別のプロジェクト (Rosetta 2 の解析や LIEF のバグ修正・改良作業) に取り組んでいたことがあり、フルタイムで解析できませんでした。 空き時間を探して、地道にこの動的なパッチがどのように施されているのかの解析を続けていました。
新しい再配置エントリーの発見
既存の dynamic relocation の仕組みを拡張するのであれば、.reloc セクションに何かしら新しいデータが追加されているのではと考え、調べてみることにしました。
すると、base relocation の末尾に見慣れないデータが追加されていることがわかりました。
この見慣れないデータを解析したところ、前節でみた動的パッチを実現するための新しい再配置エントリーであることがわかりました。
これは IMAGE_DYNAMIC_RELOCATION_ARM64X と呼ばれています *5。
実は %SystemRoot%\System32 以下に含まれる DLL は ARM64X と呼ばれる新しいアーキテクチャ向けにビルドされたバイナリとなっています。
ARM64X は ARM64 ネイティブプロセス向けのコードと x64 (or ARM64EC) エミュレーションプロセス向けの双方のコードを含みます。
そして、IMAGE_DYNAMIC_RELOCATION_ARM64X という再配置エントリーの適用により、双方のプロセスが共通の DLL を使えるようになっています。
詳細については解析記事としてまとめているので、こちらの方をご参照ください。
IMAGE_DYNAMIC_RELOCATION_ARM64X の興味深い点として、イメージ内のデータを任意の値で実行時に上書きできることがあります。
これにより、IMAGE_FILE_HEADER の Machine の値を実行時に ARM64 (0xaa64) から x64 (0x8664) に書き換えられています。
IMAGE_DYNAMIC_RELOCATION_ARM64X を見つけた時点で、難読化の 1 手法としてこの再配置エントリーを悪用するアイデアを思いつきました。
例えば、IAT への RVA を偽装する、PE ファイルヘッダーの AddressOfEntryPoint の RVA を偽装するなどです。
また、コードセクションの内容を再配置エントリーにより実行時に上書きすることでパッカーの実装としても使えるのではと考えました。
このように静的解析を妨害する用途では様々な応用ができそうでしたので、悪用についてのアイデアを資料としてまとめました。
週次のミーティングでそのアイデアを上司に話したところ、面白いので研究としてやってみてはとのコメントをもらいました。
ここからはフルタイムで研究に取り組むことができました。
IMAGE_DYNAMIC_RELOCATION_ARM64X の悪用による難読化手法について
まず、IMAGE_DYNAMIC_RELOCATION_ARM64X のパーサーと再配置エントリーを編集するツールを実装し、このツールを使い難読化の簡単なプロトタイプを実装しました。
手始めにパッカーを実装してみたところ、確かにこのコンセプトは上手くいくことが分かりました。
もちろんパッカーとして使う場合、メモリ上にコードが丸々展開されてしまいますので、メモリダンプしてしまえば簡単に解析できるというのはあります。
しかし、色々と実験をして、IMAGE_DYNAMIC_RELOCATION_ARM64X により PE のヘッダーを一部書き換えることで、静的解析もある程度困難に出来ることがわかってきました。
難読化の詳細については CODE BLUE のスライドの方をご参照ください。
ところで、再配置エントリーを利用するこうした難読化自体は割と古くから提案されており、実際にマルウェアなどで使われた事例も存在します。
他だと、2018 年の DEF CON 26 で IMAGE_REL_BASED_HIGHLOW タイプの再配置を使った難読化手法が提案されています。
この手法の場合、Windows 7 に存在するローダーの脆弱性を使う必要があり、この脆弱性が修正されている Windows 10 で利用するのは困難となっています。
また、IMAGE_REL_BASED_HIGHLOW タイプの再配置を使う場合、特定のオフセットの値を足すことしかできません。
そのため、PE ヘッダーに含まれる RVA の値として偽のエントリーを指すように変更し、解析を困難にするなどはできません。
一方、IMAGE_DYNAMIC_RELOCATION_ARM64X の場合には、Windows のローダーの脆弱性を使っているわけではありません。
そのため、今後 ARM 版 Windows において長くに渡って使える手法と言えます。
また、任意の値で上書きが出来るため、柔軟な難読化が行えます。
例えば、RVA の値として偽のエントリーを指定するといったことも可能です。
Hybrid Auxiliary IAT の発見と Microsoft による ARM64EC の発表
IMAGE_DYNAMIC_RELOCATION_ARM64X の解析とそれを悪用した難読化手法について一通りまとめた後、次は ARM64EC に含まれる .a64xrm というセクションに関心が移りました (図 7)。
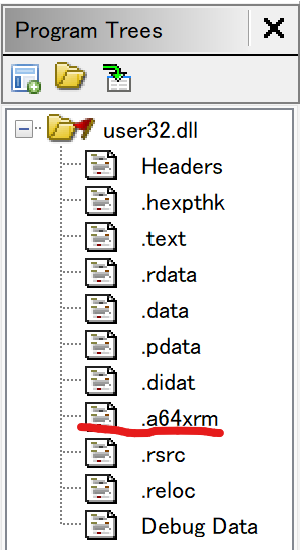
.a64xrm セクション
この .a64xrm の用途を調査する過程で Hybrid Auxiliary IAT と呼ばれるもう 1 つの IAT が ARM64EC に導入されていることを発見しました。
発見の過程や技術的な詳細については、後ほど Project Chameleon の方に記事として公開する予定です。
そして、Hybrid Auxiliary IAT について一通り解析したところで、Microsoft により ARM64EC の正式な発表がありました。 ここで ARM64EC とは何かと、それをビルドするための SDK を一般向けに提供することがアナウンスされました。 特に言及されていませんが、ARM64X ビルド用の SDK もあわせて提供されています。
この Microsoft による発表を契機として ARM64EC や ARM64X に関するディスカッションが Twitter 上で活発になりました。
私としては、正直なところ ARM64EC の SDK を一般向けに公開するとは思っておらず、ここまで大々的な発表も想定していなかったため驚きでした。 これまでの調査結果の重要度が、この Microsoft の発表により一気に高まったと感じ、急いで解析結果をまとめ、公開しました。
CODE BLUE CFP への応募と採択
この時点で CODE BLUE の CFP を募集しているというのを Twitter で目にしました。 ちょうど ARM64EC や ARM64X に関して注目が集まりつつあり、Windows 11 にも入ることが確定の状態でしたので、もしかしたら通るかもと思い CFP に応募しました。
応募に至っては作成したツールを GitHub に公開し、当日話す予定の内容を 80 枚ほどのスライドにまとめ補足資料として添付した上で行いました。
一度 CFP の期限が延長されたこともあり、採択の通知が来るまで結構時間があり、正直なところ落ち着かない日々が続きました。 そして、9 月の中旬に差し掛かる頃、ようやく採択の通知が来ました。 メーラーを開き "[CB21] Your Submission has been accepted" という件名のメールを確認した時のことは今でも忘れられません。
おわりに
以前の Black Hat EU 登壇の記事でも触れましたが、基礎技術研究室では 20% ルールがあり、業務時間の一部を自由な研究に当てることができるようになっています。 今回の研究も、新しい再配置エントリーの発見までの作業は 20% ルールの中で行われました。 振り返ってみると、ある程度自由な研究ができるこうした制度の存在が、今回の研究成果にも繋がっています。
最後に ARM 版 Windows 以外のプラットフォームとの関連についてと、今回の結果の普遍性について言及しておきます。
今回は ARM 版 Windows を対象しましたが、類似の互換性テクノロジーは M1 Mac でも実装されています。 例えば、x64 から ARM64 に命令列を変換し、その上での実行を可能とする Rosetta 2 などです。
Rosetta 2 でも ARM 版 Windows と同様に x64 から ARM64 に変換した結果をファイルとして保存する機能が備わっています*6。 このようにバイナリ変換のオーバーヘッドを削減する上で、一度変換した結果をファイルとして保存し、次の実行のタイミングで使い回す機能が実装されるのは自然と言えます。 将来的に登場するであろう互換性テクノロジーにおいても、変換結果を保存する機構が付随する可能性は高いと考えられます。
今回は ARM 版 Windows で利用可能な攻撃手法とその対策について発表しましたが、コンセプト自体は将来的に登場するであろう互換性テクノロジーにおいても適用可能な普遍的な結果と考えています。 今後も ARM 版 Windows に限らず広く互換性テクノロジーの動向について継続的に調査し、新しい脅威が存在しないか研究を進めていく予定です。
謝辞
CODE BLUE 2021 の運営の皆様には本当にお世話になりました。 今回の登壇にあたっては本当に手厚いサポートを頂きました。 この場を借りて御礼を申し上げます。
*1:Microsoft のドキュメントに従い、今回 Arm ではなく ARM と表記しています。
*2:命令セットを指す場合 A64 と表記するのが正しいですが、今回は ARM64 と記載します。
*3:Hybrid Executable Export Thunk の略と考えられます。
*4:CODE BLUE では時間がなかったため言及しませんでしたが、CHPE を導入してまで JIT バイナリ変換を避けているのには理由があります。これは JIT バイナリ変換で生成されたコードの実行が遅いためです。なぜ遅くなってしまうのかは ARM64 と x86/x64 のメモリモデルの違いが関係しています。詳細に関しては Windows Internals, Part 2 に記述があるため、こちらをご参照ください。ちなみに、M1 Mac でも同様の問題がありますが、CHPE のようなものは導入されていません。にも関わらず高速にアプリケーションを実行できるのには理由があります。これは ARM64 と x86/x64 のメモリモデルの違いの問題を M1 Chip に TSO モードを導入することにより解決しているためです。TSO モードがあるため、Rosetta 2 の AOT や JIT で生成されたコードの実行は ARM 版 Windows ほど遅くなりません。
*5:最近の Insider SDK の link.exe に含まれる文字列から MS によりこのように呼称されていることを発見しました。
*6:詳細に興味のある方は Project Champollion のリポジトリをご参照ください。