
はじめに
こんにちは。基礎技術研究部で日々セキュリティと機械学習をやっている茂木です。
今年も夏に突入し、暑い日々が続いております。と言いたいところですが、もう 9 月の末(執筆時)になってしまいました。 Black Hat USA 2022 が開催されてから少し時間がたってしまいましたね。
少し遅れてしまいましたが、今年も、「Black Hat USA 2022 注目発表 1 ~ 機械学習とサイバーセキュリティの発表紹介」と題し、"AI, ML, & Data Science" トラックの中の発表からいくつか見ていきます。「機械学習とサイバーセキュリティ」としたのは、2 つの観点があるからです。機械学習をサイバーセキュリティへ応用する考え方と、機械学習そのもののセキュリティですね。今回は両方の観点の発表を取り上げました。
昨年の記事はこちらからご覧いただけます。
Black Hat USA 2021 注目発表 2 ~ VM エスケープ脆弱性の発見と防御の発表紹介
それでは今年の発表を見ていきましょう。
- GPT-3 and Me: How Supercomputer-scale Neural Network Models Apply to Defensive Cybersecurity Problems
- All Your GNN Models and Data Belong to Me
- Malware Classification With Machine Learning Enhanced by Windows Kernel Emulation
- おわりに
- 参考文献
GPT-3 and Me: How Supercomputer-scale Neural Network Models Apply to Defensive Cybersecurity Problems
記事の執筆現在(2022 年 9 月)、Stable Diffusion[1]や Midjourney[2]などの画像生成 AI が巷を賑わせています。ところで、少し前は GPT-3[3]が注目を浴びていたのを覚えているでしょうか。(事前)学習に 460 万ドルかかるとも言われる[4]大規模なモデルである GPT-3 はテキストを生成でき、生成した文章が人間と見分けがつかないと話題になりました[5]。また、指示文(Prompt)に沿ってコード[6]や HTML[7]を生成するデモも公開されました。
本発表はサイバーセキュリティにおける防御側のツールとしての GPT-3 の活用方法を探ったものです。
本発表では活用の方向性が、大きく分けて 2 つ述べられています。①新しい種類の攻撃の検知と②攻撃の解析の補助です。
まず①新しい種類の攻撃の検知について解説します。例えばスパムメールの検知を考えてください。これはもちろん GPT-3 を使わなくとも、スパムメールとハム(スパムの反対をハムといいます)メールを大量に集め、適当な機械学習モデルを 0 から訓練することで検知器を作成できます。
一方で、GPT-3 の特徴は Prompt-based Few-shot Learning が行えることです。
これを説明しましょう。あるメールがスパムメールかどうかを Web コーパスなどによる事前学習済みの GPT-3 に判定させたいとします。このために、別のメールをいくつか用意します。それぞれ、メールの文面ととももに、それがスパムメールかどうかのラベルを付与します。これらと一緒に対象のメールを GPT-3 に与えることで、GPT-3 は対象のメールがスパムメールかどうかを判定します。
すなわち、0 からモデルを訓練することなく(事前学習については下の文で説明します)、少量のスパムメールとハムメールを推論の対象のメールと共に与えることで、スパムメールかどうかの検知ができます。
「いやいや、結局 Web コーパスで学習しているじゃないか」と思われるかもしれません。しかし重要な点は、一度事前学習を行えば、同じモデルが他のタスクにも適用できる点です。それぞれのタスクに対して大量のデータを用いて専用の検知器を作成するのではなく、1 つの事前学習済みの GPT-3 モデルにタスクの少量のデータを食わせれば、それぞれのタスクがこなせるのです。したがって、データが十分でないような新しい攻撃に対して素早い対処が可能です。これが GPT-3 の威力です。
次に②攻撃の解析の補助では、実行されるコマンドラインに対し、そのタグ付けや説明の生成が例としてあげられていました。

これは確かに有用そうですね。この②の方向ですと、コマンドラインに限らずログからその説明文を生成する、といった応用が考えられます。
さて、本発表とは別の話になりますが、ツールの紹介がなされるアーセナルにおいて、GPT-3 を用いたツールが紹介されています。ReconPal です。これは自然言語で Shodan での検索や、Nmap でのスキャンなどを行うことのできるツールです。こちらは攻撃側に近いですが、このようなツールは攻撃側・防御側の両方から今後も出てくることと思われます。
All Your GNN Models and Data Belong to Me
Graph Neural Network (GNN) はグラフ構造を対象に学習する Neural Network です。グラフというと、多くの人には画像やテキストと異なりあまり馴染みが薄く、イメージがしづらいかもしれません。例えば、SNS におけるアカウントやコンテンツの関係はグラフとしてとらえられます。これを用いて GNN で Fake News の検知をする事例があります[8]。また、タンパク質の構造もグラフ構造を持つため、GNN により構造予測を行うことができます。これを行う AlphaFold (AlphaFold2)[9]も 1 年ほど前に話題となりました[10]。
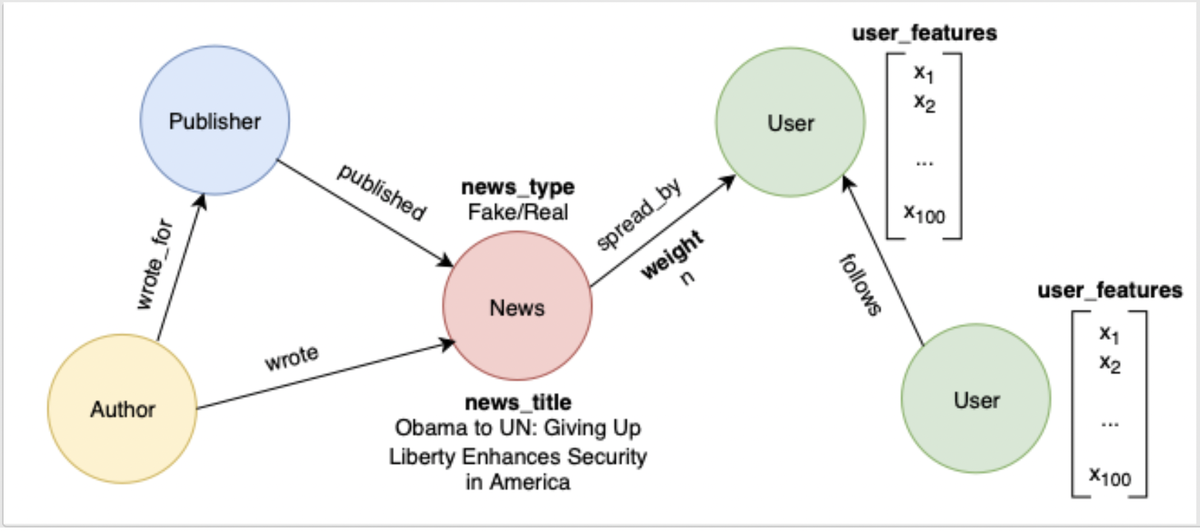
この発表は、GNN に対する攻撃、特に GNN のモデルと学習に使用したデータへの攻撃についてのものです。 ちなみに、本発表で紹介されている結果は、いずれも発表者の IEEE S&P での発表[11]や USENIX での発表[12,13]に基づいており、集大成感がありますね。
まず、学習データに関する攻撃として 3 つあげられています。
Link Re-Identification Attack
学習データのグラフのノード間につながり(エッジ)が存在するかどうかを推論する攻撃です。ちなみに論文[12]では Link Stealing Attack と呼んでいます。
Property Inference Attack
ノードの数やエッジの数などの学習データのグラフの性質を推論する攻撃です。
Subgraph Inference Attack
ある(サブ)グラフが学習データのグラフに含まれているかを推論する攻撃です。
そして、GNN のモデルを抽出・複製してしまう攻撃が (GNN の)Model Stealing Attack です。
さて、ここまでお読みになられた方は、「それで、実際どういう攻撃や被害につながるのか」と疑問に思われたかもしれません。実際、本発表では特に Real World での攻撃シナリオについて触れられていません。そこで、これについて考察します。
Model Stealing Attack については比較的被害がイメージしやすいのではないでしょうか。大きな額を投資して研究開発を行った企業秘密である機械学習モデルをそっくりコピーされるのは企業にとって脅威です。
他の 3 つの攻撃は、学習データ自体が秘密・もしくはセンシティブな属性を持っている場合に脅威となりえます。 例えば発表者が Link Re-identification Attack の脅威を述べた論文[12]では、何らかのサービスのユーザー同士のプライベートなつながりを明らかにされるケースをあげています。
発表では最後に Takeaway として 4 つの防御策を述べています。
- インフラストラクチャーをセキュアにする
- GNN の機械学習パイプラインを監査(Audit)する
- 異常を見つけるためにモデルのログを監視する
- GNN モデルのセキュリティ及びプライバシーについて評価する
ちなみに、論文[13]では Graph Reconstruction Attack という、学習データであるグラフ構造を復元する攻撃も提案されています。しかし、現状では計算量が大きく、大きなグラフへは適用できないことや、各ノードの特徴量を同時に復元できないことが課題としてあげられています。
ここからは私の考察です。発表は GNN にフォーカスしたものでしたが、実は機械学習モデル及びその学習データを対象とした攻撃は GNN に限りません。MITRE は ATLAS[14]という、機械学習システムの脅威やケーススタディをまとめたものを公開しています。また NIST は機械学習アルゴリズムへの攻撃と防御のテストベッドとなるソフトウェアを公開しています[15]。
そうした中で、Takeaway としてあげられている防御策は、全ての攻撃を防ぐことはできなくとも、いずれも GNN に限らず有効だと考えられます。
Malware Classification With Machine Learning Enhanced by Windows Kernel Emulation
タイトル通り、Windows Kernel のエミュレーション結果を使ってマルウェア検知を行った発表です。
マルウェアの検知に機械学習を用いる事例は既に多々あります。 そうした際に使われる情報(特徴量)は大きく 2 つに分類されます。静的な情報と動的な情報です。
静的な情報とは、検体を動かさずに取れる情報です。ファイルサイズや検体に含まれる文字列、ヘッダーセクションの情報などが該当します。静的な情報でマルウェアを検知する場合、マルウェアが動作する前に検知でき、被害を最小化できます。その一方で、packer による難読化などによる妨害がしやすいという欠点があります。
動的な情報とは、検体を動かすことで取れる情報です。実際に生成したファイルやレジストリの情報、使用した API、通信情報などが該当します。動的な情報でマルウェアを検知する場合、packer による難読化がなされていても、悪性の挙動を検知可能です。その一方で、マルウェアがある程度動作してから検知するため、静的な検知よりは被害が拡大しやすいという欠点があります。また、環境によって動作は変わりうるため、訓練データの作成が難しいという問題もあります。
静的な情報を用いた検知と動的な情報を用いた検知にはここに書いたこと以外も含めてそれぞれメリット・デメリットがありますが、これらの良いとこどりができないでしょうか。
そこで本発表でスポットを当てられたのが、エミュレーションです。
エミュレーションとは、実際にマルウェアを動かすことなく、エミュレーターで疑似的に動作させる手法です。これを可能にするツールの 1 つが、SpeakEasy というエミュレーターです。特に、Windows の深いところ(カーネル)までエミュレーションすることを、(Windows)カーネルモードエミュレーションといいます。SpeakEasy はカーネルモードエミュレーションによって、Rootkit のような解析の難しいマルウェアにも対応しています。
発表では、PE ファイルから抽出した静的特徴量の他に、ファイルパス、そしてエミュレーションによって得られたカーネル API のログをモデルに食わせています。
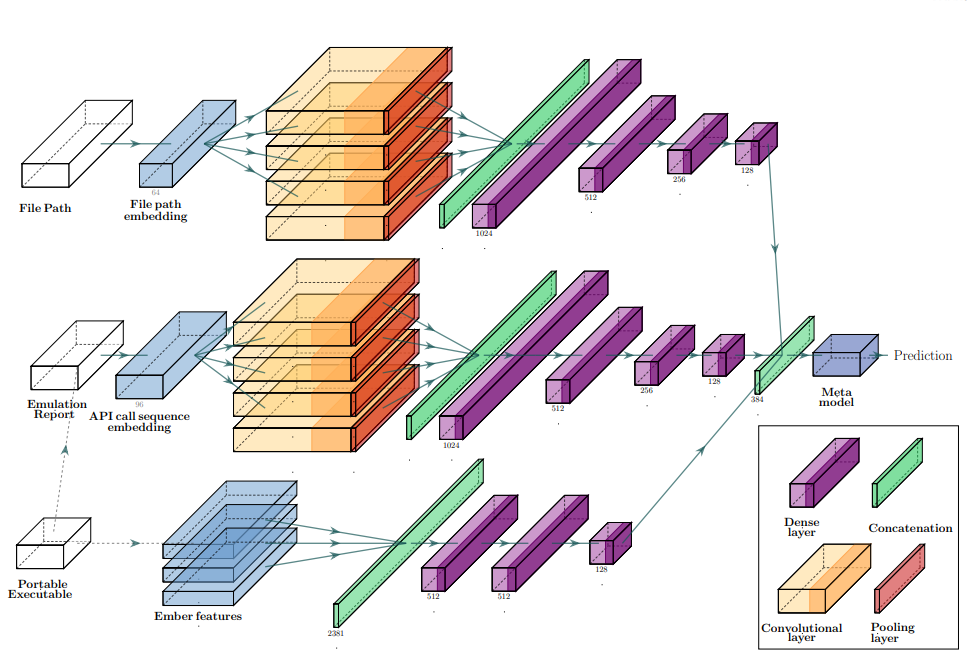
結果、上記 3 種類の情報を使用することで、過検知を抑えつつ高い精度でマルウェアを検知できています。
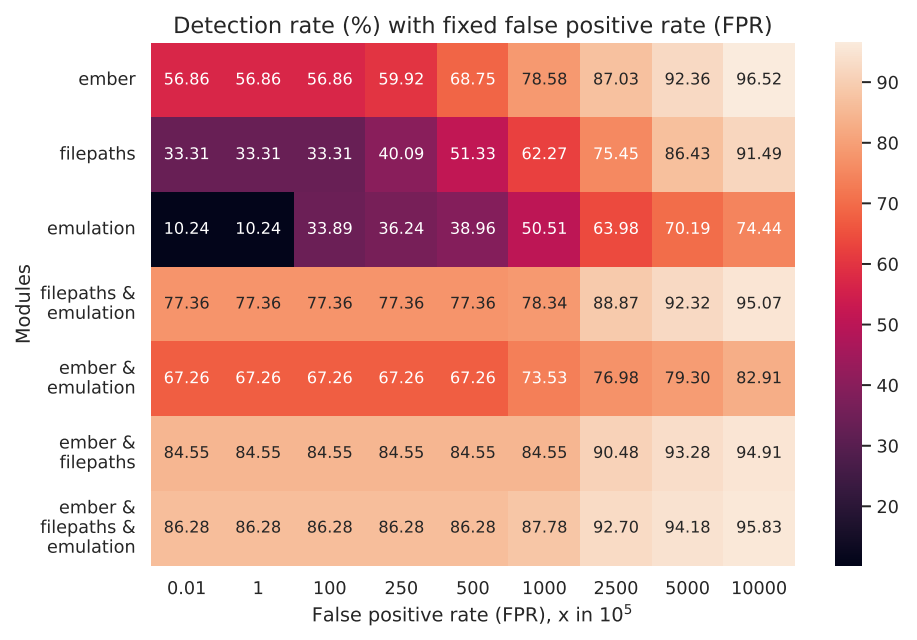
ここからは所感です。これだけ書くとエミュレーションは夢のような手法ですが、課題もあります。API などをどのようにエミュレーションするか、というのは自分たちで作る必要がある、ということです。これは単純に手間です。さらに正しい動作を実装しようとすればするほど、極論 Windows を自分たちで実装するようなものになります。これは実際不可能に近いですから、どこかで妥協することになります。例えば、実際にファイルを作成したり通信をしたりはせず、「したふり」で済ませることになります。こうすると、ある程度は疑似的に動作しますが、どこかで辻褄が合わなくなり、実際の動作とは違った状況になりえます。また大抵の場合エミュレーションは実際に動作させるよりも遥かに遅いです。
こうした問題がありつつも、前述した通り検知精度に貢献しており、やはりエミュレーションから得られる情報はマルウェア検知を行う上で有力だといえます。
おわりに
今回は Black Hat USA 2022 の発表の中から、いくつか見ていきました。 みなさまのご興味をひくものはございましたでしょうか。 今回記したものは全発表のほんの一部です。公式のサイトから各発表の資料が見られますので、ぜひチェックしてみてはいかがでしょうか。またこうした発表の他に、アーセナルでは様々なツールが紹介されています。そちらも是非チェックしてみてください。
参考文献
[1] Stable Diffusion Launch Announcement, https://stability.ai/blog/stable-diffusion-announcement , 2022 年 9 月 13 日参照
[2] Midjourney, https://www.midjourney.com/home/ , 2022 年 9 月 13 日参照
[3] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[4] OpenAI's GPT-3 Language Model: A Technical Overview, https://lambdalabs.com/blog/demystifying-gpt-3/ , 2022 年 9 月 15 日参照
[5] 大学生が GPT-3 で偽記事を作ってニュースサイトで 1 位になった方法, https://www.technologyreview.jp/s/216514/a-college-kids-fake-ai-generated-blog-fooled-tens-of-thousands-this-is-how-he-made-it/ , 2022 年 9 月 13 日参照
[6] https://twitter.com/hturan/status/1282261783147958272 , 2022 年 9 月 13 日参照
[7] https://twitter.com/sharifshameem/status/1283322990625607681 , 2022 年 9 月 13 日参照
[8] Detect social media fake news using graph machine learning with Amazon Neptune ML, https://aws.amazon.com/jp/blogs/machine-learning/detect-social-media-fake-news-using-graph-machine-learning-with-amazon-neptune-ml/ , 2022 年 9 月 27 日参照
[9] AlphaFold, https://www.deepmind.com/research/highlighted-research/alphafold , 2022 年 9 月 13 日参照
[10]「6 年解けなかった構造があっさり」──タンパク質の“形”を予測する「AlphaFold2」の衝撃 GitHub で公開、誰でも利用可能に, https://www.itmedia.co.jp/news/articles/2107/20/news136.html , 2022 年 9 月 13 日参照
[11] Shen, Yun, et al. "Model stealing attacks against inductive graph neural networks." 2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022.
[12] He, Xinlei, et al. "Stealing links from graph neural networks." 30th USENIX Security Symposium (USENIX Security 21). 2021.
[13] Zhang, Zhikun, et al. "Inference attacks against graph neural networks." Proceedings of the 31th USENIX Security Symposium. 2022.
[14] ATLAS, https://atlas.mitre.org/ , 2022 年 9 月 13 日参照
[15] Dioptra, https://pages.nist.gov/dioptra/ , 2022 年 9 月 13 日参照