
はじめに
基礎技術研究部リサーチ・エンジニアの加藤です。
2023 年 11 月 8, 9 日の 2 日間に亘って開催された CODE BLUE 2023 に参加しました。
本記事では、私が聴講した講演の中から特に興味を惹かれた「シンボリック実行とテイント解析による WDM ドライバーの脆弱性ハンティングの強化」を紹介します。この講演は発表者の Zeze Lin 氏によってスライドが公開されているため、そちらもご参照ください。
この発表で扱われたツールは "IOCTLance" と呼ばれ、検証に使われたドライバーのデータセットなどと共にソースコードが GitHub で公開されています。本記事ではこのリポジトリからソースコードを参照し、動作や特徴をコードベースで解説します。
なお、ソースコードは本稿執筆時点における最新コミット (73e6e32)を参照しています。今後このリポジトリにおいて変更が行われた場合に、本記事の内容や参照している行番号等が最新のコミットと異なる可能性があります。
技術的な背景
発表を紹介する前に、この発表で対象としている WDM ドライバーと、解析手法として使われているシンボリック実行とテイント解析について簡単に説明します。
WDM ドライバー
この発表で対象としている WDM ドライバーは、Windows Driver Model と呼ばれる Windows におけるデバイスドライバーのフレームワークに準拠したドライバーです。ユーザーモードのアプリケーションがドライバーの機能を利用する際は、Windows API を用いて I/O マネージャーにリクエストを送信します。よく用いられる API として DeviceIoControl が挙げられます。この API は制御コードと入出力用のバッファーを引数にとり、対応する操作をドライバーに行わせる API です。
アプリケーションからリクエストを受け取った I/O マネージャーは、ドライバーに渡す I/O Request Packet (IRP) を構成してそのポインタをドライバーに渡します。DeviceIoControl の引数として渡される入出力バッファに関する情報や I/O 制御コードは、I/O スタックロケーションという構造として、この IRP に含まれています。I/O スタックロケーションはIO_STACK_LOCATION 構造体で定義されており、Parameters メンバーは、各操作固有の引数が格納される共用体となっています。
以下の図はユーザーモードのアプリケーションが、DeviceIoControl を用いてドライバーに制御コードを送信し、操作する際のイメージを示しています。
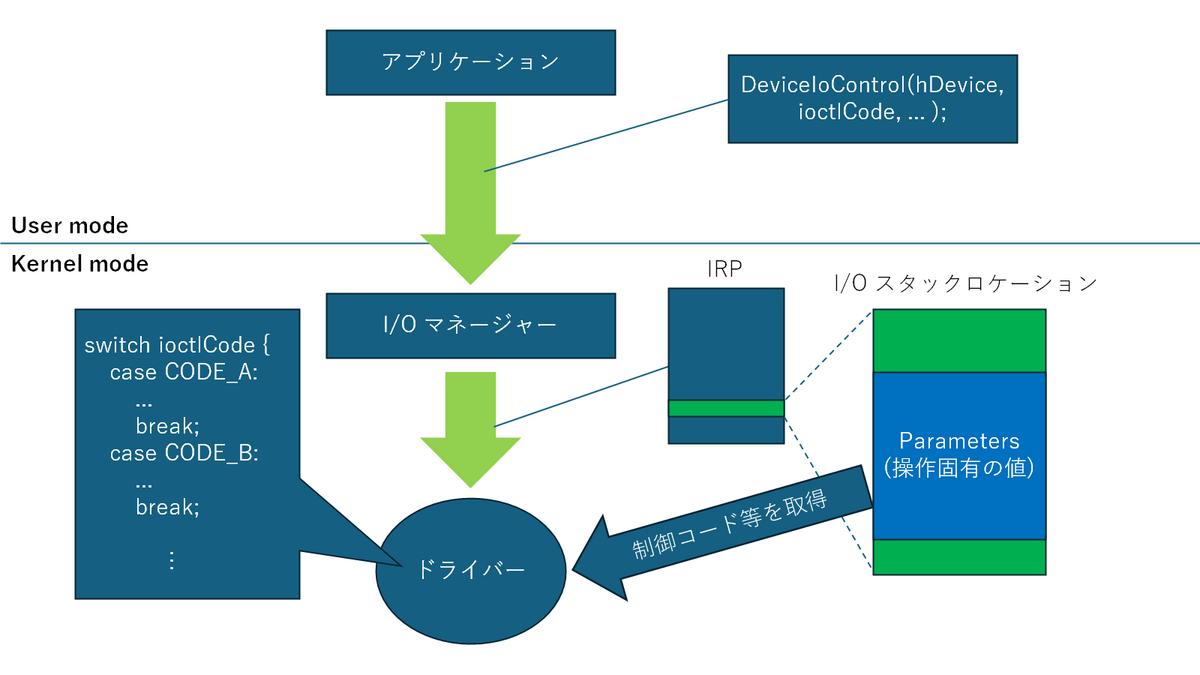
カーネルモードにおいては、全てのドライバーと OS が 1 つの仮想アドレス空間を共有しているため、ドライバーにバグが存在すると、他のドライバーや OS に影響を与える可能性があります。特に、任意メモリの読み書きのような操作が可能な場合は BSOD のような DoS や権限昇格のような深刻な脆弱性へと繋がることがあります。このことから、ドライバーのセキュリティを担保することは開発する上で極めて重要です。
本記事で紹介するツールである IOCTLance では、シンボリック実行を用いて DeviceIoControl の呼び出しをシミュレートする形でドライバーの脆弱性を探しています。シンボリック実行の前に IRP や、I/O スタックロケーション (制御コードや入力バッファ等の情報がある) を構成する処理がソースコードに見られます。
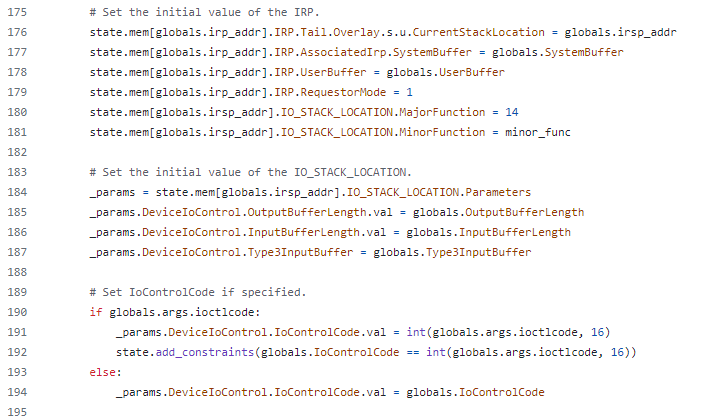
analysis/ioctlance.pyの 175 行目より)
シンボリック実行
続いて、バイナリ解析手法として扱われているシンボリック実行についても触れます。シンボリック実行は、通常の実行であれば値が代入される変数をシンボルとして扱って実行し、シンボルに対して行われた演算や操作を元にしてプログラムを解析する手法です。シンボル化する対象としてはメモリやレジスタ、ファイルやソケット通信の内容などが挙げられます。
シンボリック実行の主な用途として、通った実行パスの制約からそのパスを通るための具体的な値を求める事があります。具体的な値の代わりにシンボルが使われているため、実行中にシンボルに対して行われた演算が抽象構文木のような形で記録されています。これによって、分岐命令においてシンボルがどのような条件を満たして分岐したかということがわかります。これらの条件を制約ソルバーに入力して解かせることで、その実行パスを通るための具体的な値を求めることが可能です。
簡単な例として、以下の Python のコードを用います。
# 本来のプログラムでは、x は次のようにユーザーによって値が入力される # x = int(input("x: ")) x = sym_x # 具体的な値の代わりに x に sym_x というシンボルを代入 # 本来のプログラムでは、y は次のようにユーザーによって値が入力される # y = int(input("y: ")) y = sym_y # 具体的な値の代わりに y に sym_y というシンボルを代入 z = x + y # z = sym_x + sym_y # 具体的な値は計算されず、sym_x と sym_y の和という形で AST にエンコードされている if z == 2: # True となる制約: [sym_x + sym_y == 2] if x > 0 and y > 0: # True となる制約: [sym_x + sym_y == 2, sym_x > 0, sym_y > 0] print("target path") else: # こちらを通る制約: [sym_x + sym_y == 2, (sym_x <= 0 || sym_y <= 0)] print("not target path") else: # こちらを通る制約: [sym_x + sym_y != 2] print("not target path") # print("target path") を通る入力 x, y を求めたい # この地点の制約: [sym_x + sym_y == 2, sym_x > 0, sym_y > 0] を満たす整数 sym_x, sym_y をソルバーに解かせる # -> sym_x = 1, sym_y = 1が得られる
後半の if が入れ子になっている箇所で print("target path") が実行されるような、入力 x, y を求める場合を考えます。if の条件となる式にシンボルが含まれている場合、その時点での状態を複製して条件の真偽ごとにそれぞれ実行することで、各分岐の満たす条件が分岐ごとに記録されます。上のコードにおいて、先頭の if である if z == 2: を例にとって考えると、真偽ごとにそれぞれ sym_x + sym_y == 2 と sym_x + sym_y != 2 という条件が記録されます。これを繰り返して目標としている箇所に到達したり、全てのパスを網羅するといった形でシンボリック実行によるパス探索を終了すると、通ったパスに対する制約が得られます。目標としているパスを選択して記録された条件を制約ソルバーに入力して解かせることで、シンボルがどのような値をとるとこのパスに到達するかが求まります。
テイント解析
発表で使われているもう 1 つのバイナリ解析手法が、データがプログラムの実行を通してどのように伝搬していくかを調べるテイント解析です。この手法は、外部入力を受け付ける処理のようなデータの源となる箇所 (テイントソース) とデータの影響を受ける箇所 (テイントシンク) を定義し、ソースからシンクまでのデータの流れを解析します。ソースから入ってきたデータが代入や演算によって影響を及ぼす先にタグを付け、タグを付けられた箇所が他の箇所に影響を及ぼす場合もタグを付けるような形で、シンクに伝搬するかを調べます。
簡単な例として、以下の C 言語のコードと単純なスタック上のメモリレイアウトを用います。
char buf1[0x10]; char buf2[0x8]; char buf3[0x8]; /* スタック上で 8 バイトごとに次のような構造だとする (上に行くほどアドレスが小さい) buf1: ........ ... : ........ buf2: ........ buf3: ........ */ // argv[1] をテイントソースとする // buf1 の先頭から 0x10 バイトまでタグが付く memcpy(buf1, argv[1], 0x10); // テイントシンク (1) /* buf1: XXXXXXXX ... : XXXXXXXX buf2: ........ buf3: ........ */ // buf2 の先頭から 0x10 バイトまでタグが付く // buf2 の真下に buf3 が存在するため、buf3 内にもタグが付く memcpy(buf2, buf1, 0x10); // テイントシンク (2) /* buf1: XXXXXXXX ... : XXXXXXXX buf2: XXXXXXXX buf3: XXXXXXXX */
各変数がスタック上でどのメモリを使うかはコンパイラに依存しますが*1、ソースコードのコメント中にもあるように buf1、buf2、buf3の順でアドレスが小さい方に配置される場合を考えます。第一引数をテイントソースとすると、1 回目の memcpy によって buf1 内のメモリがタグ付けされます。続く 2 回目の memcpy では、既にタグが付いている buf1 から buf2 にコピーするため、buf2 内のメモリがタグ付けされます。ここで、コピーしているサイズは 0x10 バイトであり、buf2 のサイズである 0x8 バイトを超えていることから、その下の buf3 にも書き込みが行われます。これによって buf3 内のメモリにもタグ付けが行われます。
IOCTLance では、IRP に含まれるバッファーやその長さをシンボル化しており、シンクにおける変数がこのシンボルを含んでいるかを調べることでデータが伝搬しているかどうかを調べています。これは analysis/utils.py というファイルにおいて tainted_buffer という関数で実装されており、次に示すソースコードはその実装になります。
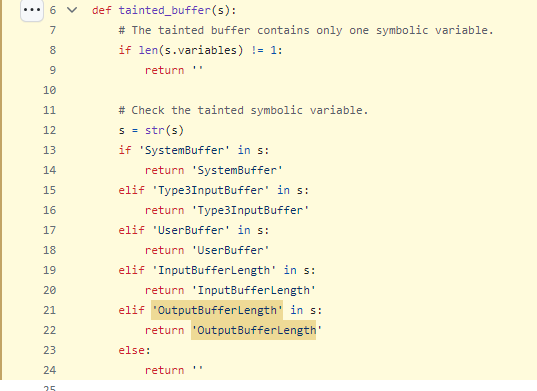
シンボリック実行やテイント解析は強力な手法ですが、パスやデータの伝搬先を全て調べるという性質上、コードサイズが大きいソフトウェアに対して適用すると組み合わせ爆発が発生します。この問題に対処するには探索範囲を枝刈りしたり探索したいパスの特徴によって探索方式を変えたり (例えば、幅優先探索から深さ優先探索に変える) といった工夫が必要です。
IOCTLance
この発表では、発表者が開発した "IOCTLance" という Python 製のツールが紹介されました。シンボリック実行エンジンとして、同じく Python 製のシンボリック実行フレームワークである angr が使われています。ドライバーの解析は analyze_driver という関数を起点として、次のようなデザインに従って行われています。
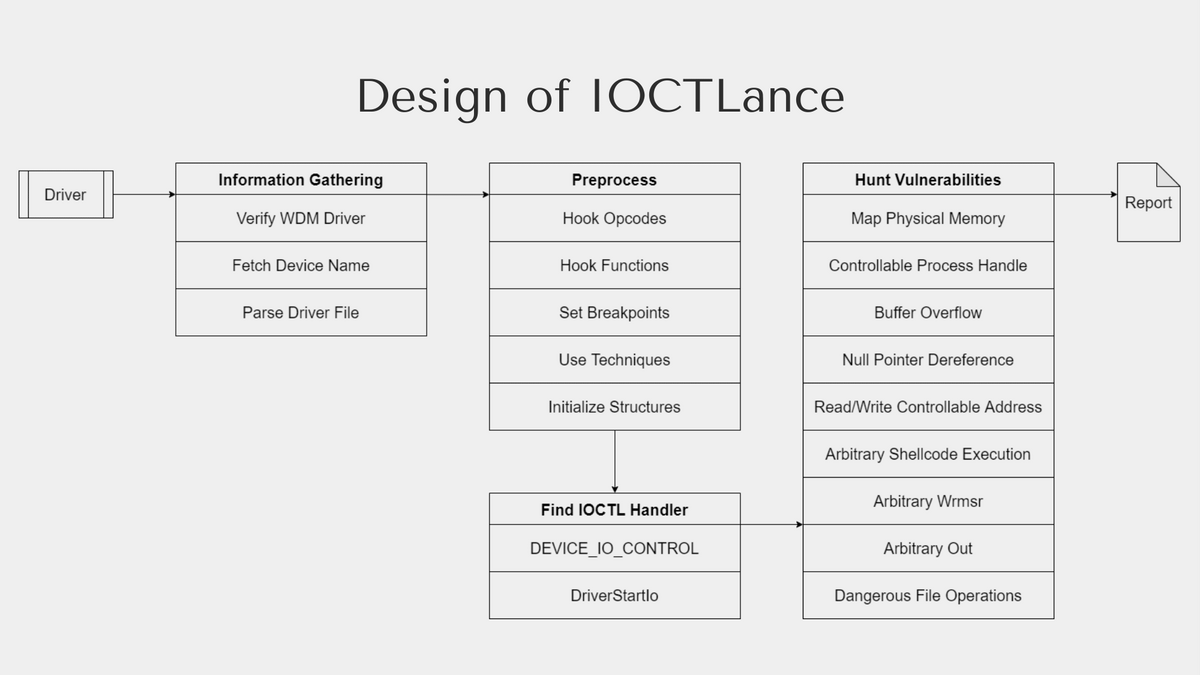
ドライバーを読み込んだ後にまず行われるのは表層情報の解析です。ここでは WDM ドライバーかどうかの判定やドライバー名の取得といった基本的な情報の取得に加えて、解析で用いる関数シンボルのアドレス取得等が行われます。
続いて、この解析で見つかった関数や命令を元にしてフック関数やブレークポイントを設定します。ブレークポイントは特定アドレスへの読み書きの監視や間接ジャンプの解析を最適化するために用いられます。なお、シンボリック実行では CPU 上で実際に実行するのではなくエミュレーションを行うことから、ここでいうブレークポイントはデバッガで用いられるものとは異なり、angr 独自のものとなっています。IOCTLance では用途別にブレークポイントが定義されており、analysis/breakpoints.py からその一覧を確認できます。
この後、入力に対してドライバーがどの操作をするかを決める IOCTL Handler を探します。これは特定のアドレスにハンドラを指すポインタが書き込まれることから、そのメモリへの書き込みを監視するb_mem_write_ioctl_handlerという名前のブレークポイントを設置してシンボリック実行中に検知するという方法で取得します。対応する関数は find_ioctl_handler であり、この関数内においてブレークポイントを設置する処理や for ループによるシンボリック実行の処理が確認できます。

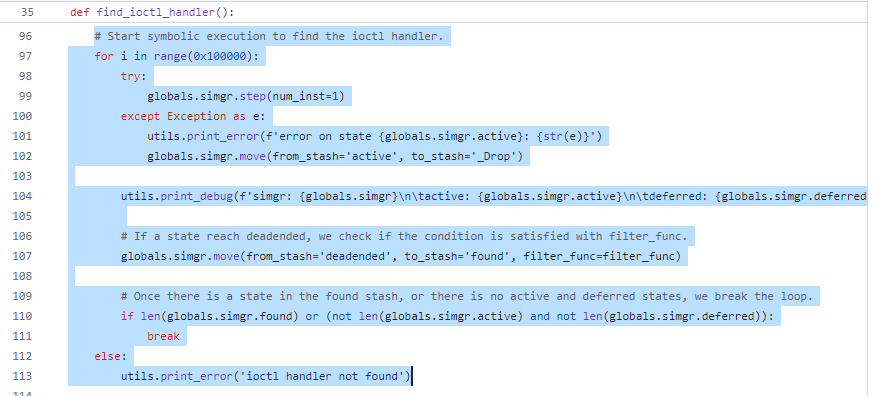
ハンドラのアドレスが判明したので、バッファや制御コードをシンボル化した IRP を用いてハンドラを呼び出す状態を作成してからシンボリック実行を新たなコンテキストで行います。これは hunting という関数で行われており、名前の通り、脆弱性を見つけることがメインの処理です。
以下は検出対象となる脆弱性の一覧です。

発表スライド中ではこの図に続いて、それぞれの脆弱性がどのようなコードで生じ、どのような影響があるのかの説明がありましたが、紙面の都合上全てを引用するのは難しいため軽く説明を加えます。
- map physical memory: 任意の物理メモリに対応する仮想アドレスを得ることで、カーネル空間中のメモリへの読み書きを実現し権限昇格に繋がる
- controllable process handle: 操作の対象となるプロセスハンドルを制御出来ることで、アクセス制御を回避して他プロセスへの操作が行える
- buffer overflow: バッファオーバーフローによってカーネル空間中のメモリを破損し、DoS や権限昇格に繋がる
- null pointer dereference: ヌルポインタ逆参照によって DoS が発生する
- read/write controllable address: 制御可能なアドレスへの読み書きによって DoS や権限昇格に繋がる
- arbitrary shellcode execution: 任意のシェルコードをカーネル空間中で実行する
- arbitrary wrmsr: MSR レジスタへの書き込みを行う wrmsr オペコードに任意の引数を指定可能なことで、権限昇格に繋がる
- arbitrary out: I/O ポートへ値を出力する out オペコードに任意の引数を指定可能なことで、DoS が発生する
- dangerous file operation: 任意のファイルを削除するといった危険なファイル操作が実現する
IOCTLance ではこれらの脆弱性へと繋がる可能性がある API をフックし、入力が引数に影響を及ぼすかどうかを解析して脆弱性を探しています。そのようなフック関数は analysis/hooks.py から確認出来ます。この中から buffer overflow (特に memcpy 関数においてサイズを自由に指定出来ることによるもの) を例にとって紹介します。
memcpy 関数におけるバッファオーバーフローの検出はそのフック関数内において、次のようなコードによって行われています。
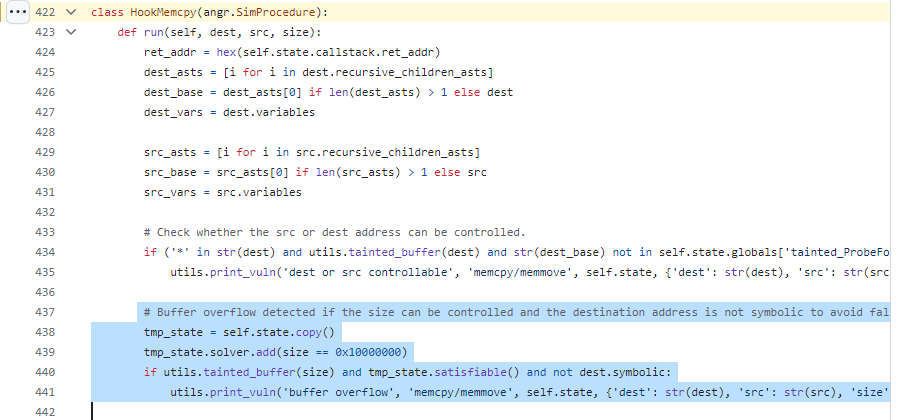
memcpy のフック関数においてバッファオーバーフローを検出する処理
このコードでは、memcpy 関数が呼ばれた際に第 3 引数である size 変数が制御可能かまたは、大きな値 (0x10000000) を設定出来るかを確認しています*2。前者はテイント解析によって IRP 中のバッファがここへ伝搬するかを調べており、後者は size == 0x10000000 であるという制約を加えてこれを満たす場合があるかを調べています。どちらも満たす場合は、第 2 引数の dest 変数に 0x10000000 のような明らかにバッファサイズを超えるサイズのデータを書き込むことになるため、バッファオーバーフローが発生すると見做されます。
工夫点
これまで挙げたような機能を高いパフォーマンスで実現するために IOCTLance には様々な工夫が施されています。IOCTLance に限らずシンボリック実行ツールでよく用いられる手法として、命令や関数をフックして独自の処理を実装するというものが考えられます。ここでは命令のフックとして rep mov* や rep sto* のような繰り返しを行う命令のフックを取り上げます。
rep movsb や rep stosb のような rep というプレフィックスから始まる命令は、rcx レジスタの値に応じて、rdi レジスタが指すバッファに対して値を格納する命令です。命令ごとに格納する値のビット数や挙動*3は異なりますが、rcx レジスタの分だけ格納を繰り返すという挙動は共通しています。
rcx レジスタがシンボル化されている場合、繰り返しの回数として取りうる値の組み合わせが多くなり、パスの分岐が増える可能性が考えられます。また、繰り返しの回数に大きな値が指定されてシンボリック実行のパフォーマンスに影響を与えることも考慮し、これらの命令をフックして次のような制限を加えています (rep movsb の例)。
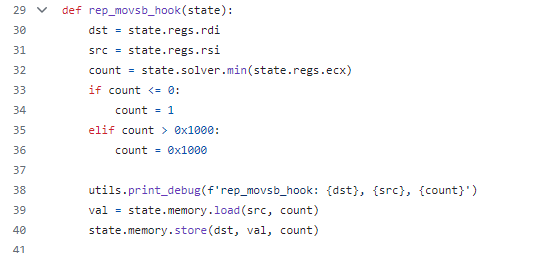
rep movsbに対するフック (analysis/opcodes.py の29行目から)
rcx がシンボル化されている場合は取りうる最小の値を計算して固定の値とし、それと 0x1000 を比べて小さい方が繰り返しの回数として用いられています。これによって、繰り返し回数をシンボルから具体的な値にした上で回数を最低限の値に設定してパスの爆発を抑制しています。
このような x86 の命令に加えて、前述した memcpy のような関数に対してもフックが行われています。その上で 1 つ問題になることとして、memcpy や memset のような関数はコンパイラによって組み込みの独自関数がインライン展開されて用いられることがあります。これらの関数の開始地点を angr が自動で特定することはないため、IOCTLance では命令のパターンマッチングによって検出し、見つけたアドレスにおいてフック関数を設定しています。以下はこの処理を行っている find_hook_func 関数のソースコードです。
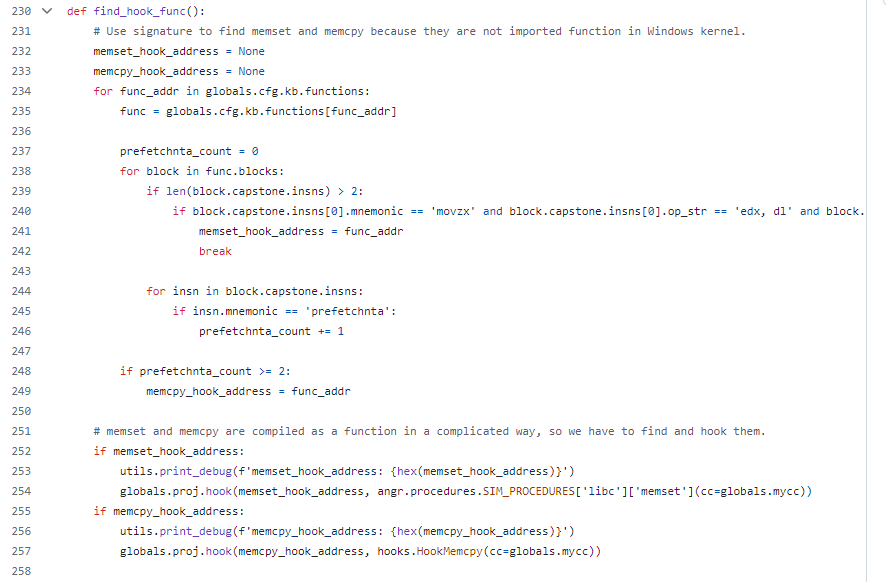
memset と memcpy のアドレスを特定する処理
また、パフォーマンス向上以外の工夫点として、制約を回避するために本来であれば具体的な値が入っている箇所をシンボル化する手法を紹介します。
PsGetVersion や RtlGetVersion といった関数は名前の通り OS のバージョンを取得するための関数で、バージョンのチェックに使われることがあります。シンボリック実行においてこの関数が呼ばれた際に、バージョンを具体的な値として返すような実装になっていると、このチェックに引っかかって終了する可能性があります。これを防ぐための方法として、予め有効なバージョンを調べておき関数フック時に設定するという方法が考えられますが、この方法ではドライバーごとに事前の解析が必要になります。
これに対して、IOCTLance ではこれらの関数をフックし、バージョンとしてシンボルを返しています。これによってチェック時の分岐条件はシンボルを参照することから、実行パスは増えてしまいますが、必ずチェックを回避出来るパスが実行され、終了することが無くなります。
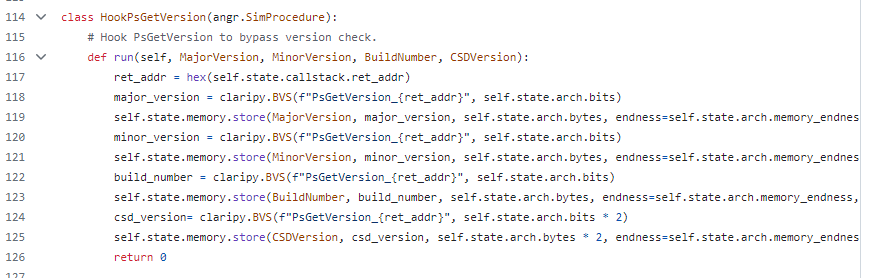
PsGetVersion のフック関数において、バージョン情報をシンボル化してバージョンチェックを回避する処理
性能評価
これまで説明したような機能と工夫によって、IOCTLance は次のような成果を挙げています。既知の脆弱なドライバーを集めたデータセットである namazso/physmem_drivers と CaledoniaProject/drivers-binaries に対しては、対象としている脆弱性タイプにおいて既知のほとんどの脆弱性を発見しました。テスト用に作られた脆弱なドライバーを含むデータセットではありますが、典型的な脆弱性の多くをこのような自動解析で発見出来ているという驚異的な性能です。

続いて、実製品として使われているドライバーに対しての評価がこちらです。318 個の対象ドライバーを解析したところ、26 個のドライバーにおいて合計 117 個の脆弱性が発見され、製品レベルのドライバーに対しても有効なツールであることが示されました。

おわりに
CODE BLUE 2023 では今回扱った発表以外にも多くの興味を惹かれる発表がありました。特に、「Pwn2Own のターゲットをハッキングした 3 年間の物語:攻撃、ベンダーの進化、そして教訓」や「開けゴマ!スマートロック開錠の全容」はどちらもハードウェアを対象としており、普段ソフトウェアのセキュリティにばかり目を向けている私としては新鮮で興味深い発表でした。加えて、どちらの発表も長期間に亘って 1 つの製品へ取り組んだことを扱っており、粘り強く取り組むことの大切さが伝わる講演でした。
基礎技術研究部では数年先の脅威を見据えた研究をミッションとしていることから、CODE BLUE のような最新研究が多く発表されるカンファレンスへの参加は大きな刺激になりました。今後もこのような機会があれば積極的に参加し、持ち帰った知見を社内外へと還元していきたいと考えています。
エンジニア募集
FFRIセキュリティではサイバーセキュリティに関する興味関心を持つエンジニアを募集しています。 採用に関しては採用ページをご覧ください。