
はじめに
FFRIリサーチエンジニアの中川です。
先日ソースコード可視化ツール Sourcetrail が OSS として公開されました。本記事では Sourcetrail の導入方法と簡単な使い方について、radare2 のソースコードリーディングを例として説明します。
Sourcetrail について
ソフトウェアエンジニアの方は (人にもよるかと思いますが) スクラッチでコードを書くより、社内にある既存コードに新規機能を追加したり、既存機能を修正することのほうが多いかと思います。その際、他の人によって書かれたソースコードの読解がまず必要です。
こうした際、型の定義・caller・callee を頻繁に確認することになります。もちろん、IDE や GNU GLOBAL などを使えば確認できますが、(私の主観になりますが) 見やすいとは言い難いです。
こうした問題を解決してくれるのが Sourcetrail です。
Sourcetrail はそのプロジェクトのソースコードを解析した上で、変数の参照・caller・callee などの情報をグラフベースで表示してくれます。言葉で説明するよりも図で見たほうが早いと思いますので、下の図 1 を見てください。図 1 は Sourcetrail でテストプログラムを開いた際の表示画面です。左側のペインには graph が、右側には現在 graph で選択している箇所に該当するソースコードが表示されています。
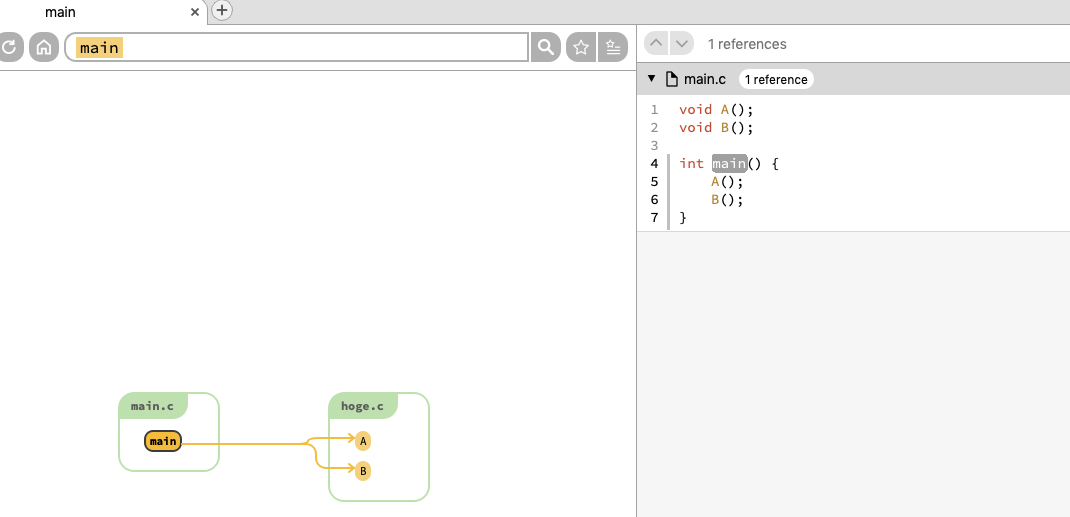
図 1 を見ると、main 関数から A と B という関数に向かって 2 つの矢印が出ていることがわかります。これは main 関数が A B の 2 つの関数を呼び出していることを意味します。
さて、A という関数をクリックしてみましょう。すると図 2 のように変化します。
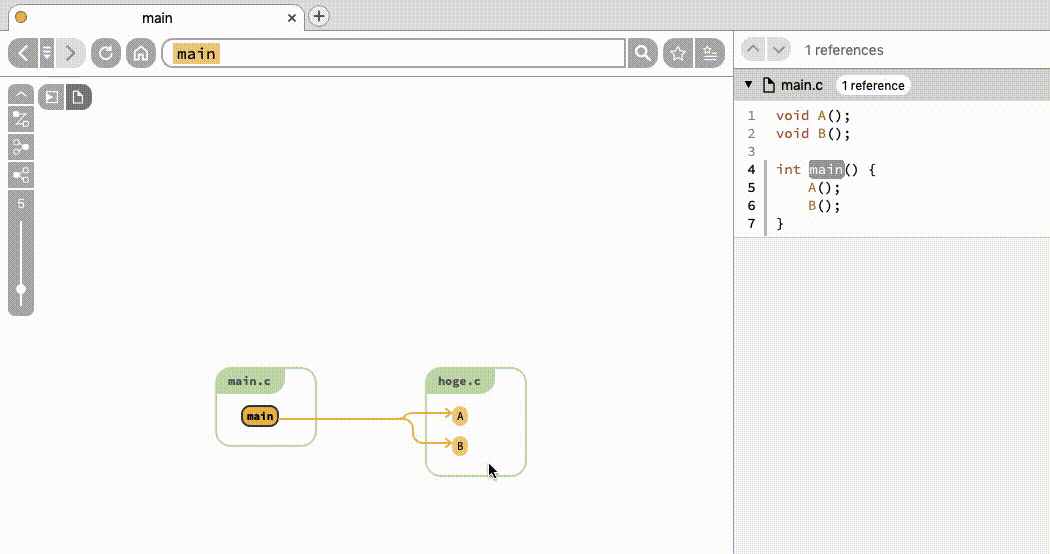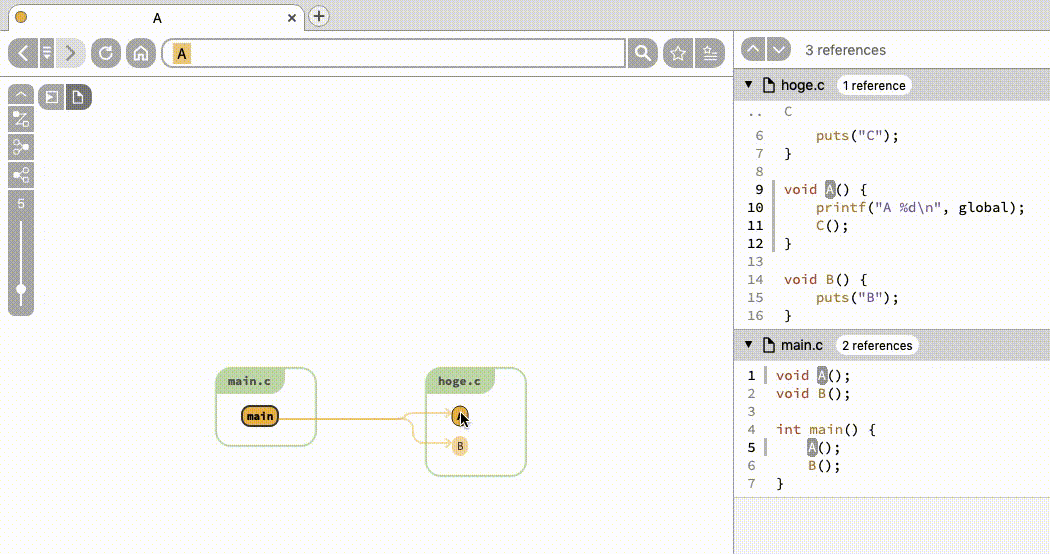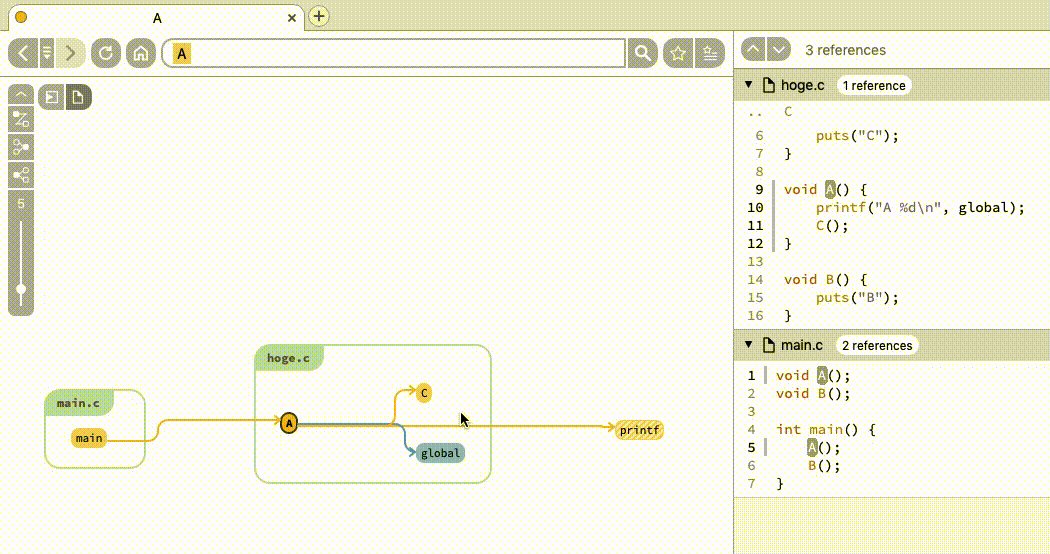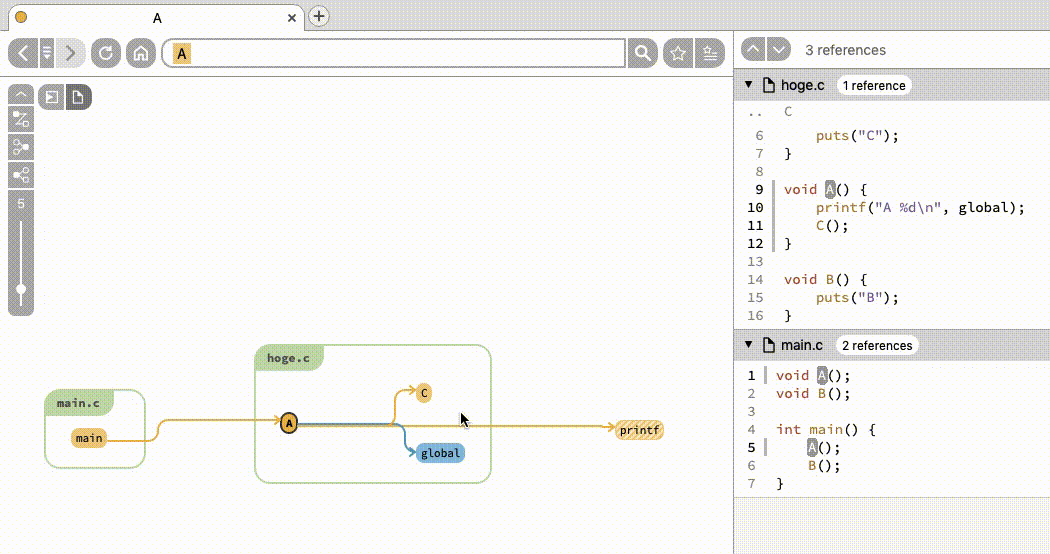
caller・callee・参照しているグローバル変数がノードとして表示されることがわかります。変数や関数の参照先・元の一覧を取得したいと思った場合、簡単にできますね。
また、関数・変数・ファイル名によるファジー検索機能もサポートされています。左上の検索窓に検索したいクラス名・変数名を打ち込むと、名前が正確にマッチせずとも、探したい関数・クラスの検索結果が表示されます。
radare2 について
次に、本記事でソースコードリーディングの対象とする radare2 について簡単に説明します。
radare2 は高機能な OSS の逆アセンブラです。「逆アセンブラといえば IDA Pro」という状況が長らく続いていましたが、radare2・radare2 の GUI 版の Cutter 、NSA の Ghidra などが近年出てきました。
radare2 は TUI ベースで、サポートしているアーキテクチャ・ファイルフォーマットが他の逆アセンブラに比べて多いのが特徴です。GitHub のリポジトリを見ても非常に活発に開発が行われており、今後さらなる発展が期待できます。
radare2 はカスタマイズしやすいように設計されており、新しいファイル形式向けのパーサーなどをプラグインとして導入できます。
残念な点として、プラグイン作成方法についてわかりやすく解説した記事が無いことが挙げられます。radare2 book に一応記載がありますが、概要が記されているだけで、ソースコードを読まなければ詳細は分からない状態です。
ただ、radare2 はなかなかソースコード量が多いので、プラグイン作るためにソースコードを読むにしても中々骨です。必要な構造体の定義・ユーティリティ系の関数として radare2 が用意してくれているもののうち、どれを使えばよいのかを把握するのに時間がかかります。
そこで、「Sourcetrail を使って、このソースコードを読む作業を効率化しよう!」となるわけです。
Sourcetrail の C 言語プロジェクトの作成
まずは radare2 用に Sourcetrail プロジェクトを作成します。
radare2 は C 言語で実装されています。Sourcetrail で C 言語のプロジェクトを読み込ませるためには JSON Compilation Database を作成する必要があります。
JSON Compilation Database はコンパイル時のコマンド (インクルードパス・コンパイルフラグ) が記録された JSON ファイルのことです。以下に JSON Compilation Database の一例を示します。コンパイル時のコマンド、どのディレクトリでこのコマンドを実行したのかが記述されていることがわかります。
[ { "arguments": [ "/usr/bin/gcc", "-c", "-o", "a.out", "hoge.c" ], "directory": "/home/nakagawa/sourcetrail_demo", "file": "hoge.c" }, ... ]
この JSON Compilation Database ですが、CMake を使っているプロジェクトであれば、CMAKE_EXPORT_COMPILE_COMMANDS フラグを有効にするだけでエクスポートすることが可能です。また、CMake を使っていないプロジェクトでも、bear というツールを使うことで、エクスポートすることが可能です。
bear を使って radare2 向けに JSON Compilation Database を生成します。
$ sudo apt -y install bear # bear の導入 $ git clone https://github.com/radareorg/radare2.git && cd radare2 $ ./configure $ bear make all # bear の後にビルドコマンドを入力
ビルド後に同じディレクトリに compile_commands.json ができるのが確認できます。これが、JSON Compilation Database です。
後は Sourcetrail を開き Source Group を作成する際に compile_commands.json を指定すれば OK です。
radare2 のソースコードリーディング
さて、いよいよ本題の radare2 のソースコードリーディングに入ります。今回は例として PE ヘッダのパースを行っている周辺の処理を、Sourcetrail を使って見ていきます。
PE を扱っているファイルを探す
まずは PE 構造体を探しましょう。左上の検索窓に適当に pe と打ってみます (図 3)。

すると pe.c というファイルが検索の上位にヒットします。これをクリックして pe.c ファイルに定義されている関数・構造体・変数の一覧を表示します。
pe.c ファイルに定義された関数を一つずつ見ていくと、Pe32_r_bin_pe_obj_t という構造体を第一引数にとっているものが多いことがわかります。
この段階ではまだ推測でしか無いですが、これがパースした PE のデータを保持している構造体のようです。
Pe32_r_bin_pe_obj_t の定義へ飛ぶ
Pe32_r_bin_pe_obj_t をクリックします(図 4)。

構造体のメンバーを見ていると dos_header nt_headers などがずらずらと並んでいます。どうやら推測はあたっていたみたいです。
グラフビューの方を見ると、Pe32_r_bin_pe_obj_t となっていますが、ソースコードの方を見ると PE_(r_bin_pe_obj_t) となっています。この PE_ ですが、マクロになっていて、定義は以下のようになっています。
#ifdef R_BIN_PE64 #define PE_(name) Pe64_ ## name #define ILT_MASK1 0x8000000000000000LL #define ILT_MASK2 0x7fffffffffffffffLL #define PE_Word ut16 #define PE_DWord ut64 #define PE_VWord ut32 #else #define PE_(name) Pe32_ ## name #define ILT_MASK1 0x80000000 #define ILT_MASK2 0x7fffffff #define PE_Word ut16 #define PE_DWord ut32 #define PE_VWord ut32 #endif
要するに、64bit の場合には Pe64 というプレフィックスをつけ、そうでない場合には Pe32 というプレフィックスをつけるマクロです。C++ でのテンプレートクラスを C のプリプロセッサで実装しているといえばわかりやすいでしょうか。
Sourcetrail はこのようにプリプロセッサが使われていた場合でも、マクロが展開された後の構造体名で表示してくれます。この辺りは GNU GLOBAL などではできないですね。
パースしている箇所を探す
今回はパースしている箇所を探したいので、Pe32_r_bin_pe_obj_t の各メンバーを参照している関数を探していきます。dos_header をクリックします(図 5)。
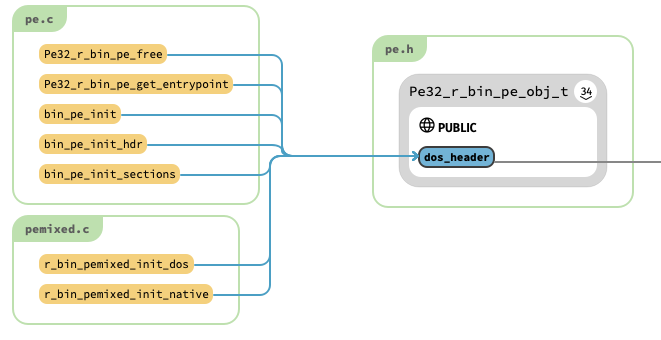
参照している関数の中に bin_pe_init_hdr というのが見つかります。hdr は header の略でしょうか? bin_pe_init_hdr の定義を見てみます。
static int bin_pe_init_hdr(struct PE_(r_bin_pe_obj_t)* bin) { if (!(bin->dos_header = malloc (sizeof(PE_(image_dos_header))))) { r_sys_perror ("malloc (dos header)"); return false; } if (r_buf_read_at (bin->b, 0, (ut8*) bin->dos_header, sizeof(PE_(image_dos_header))) < 0) { bprintf ("Warning: read (dos header)\n"); return false; } ... }
Pe32_image_dos_header 構造体のサイズ分、ヒープに領域を確保し、bin->b の先頭から同サイズのデータを読み込み、確保した領域へと書き込んでいる処理が見つかりました。
コードを見た感じでは、bin->b が raw data で、パースした結果を Pe32_r_bin_pe_obj_t の各メンバーに一つずつコピーしているように見えます (実際そうです)。
その他の PE ヘッダーのフィールドについても同様で、この bin_pe_init_hdr 内で raw data からパースした結果を Pe32_r_bin_pe_obj_t の各メンバーに書き込む処理が続きます。
こんな形で、Sourcetrail を使えば簡単に radare2 で PE ヘッダーをパースしている箇所を特定することができます。
おわりに
Sourcetrail の導入方法・機能と、Sourcetrail を使った radare2 のソースコードリーディングについて紹介しました。
私はこれまで emacs + GNU GLOBAL を使って radare2 のソースコードリーディングをしていたのですが、Sourcetrail の導入により、ソースコードリーディングのスピードが格段に上がったと感じています。
ここでは紹介しなかったですが、各種 IDE やエディタと連携する機能も Sourcetrail は備えています。これを使えば、現在 Sourcetrail で表示している箇所をお好みの IDE やエディタで表示することができます。
この記事が C や C++ の大規模プロジェクトのソースコードリーディングをしている方のお役に立てれば幸いです。