
はじめに
FFRI セキュリティエンジニアの岡野です。 近年流行の機械学習を、手軽に実施できるライブラリとして注目されているKeras(+TensorFlow)を利用した、画像認識を紹介します。
本稿では、一般画像を用いた画像の学習と識別結果を掲載し、その応用として、マルウェアが利用する偽装アイコンと非偽装アイコンの識別を試した結果を掲載します。
TensorFlowとKerasの概要
TensorFlow
TensorFlowは、Googleが開発し、2017年2月15日にリリースされたオープンソースの機械学習用ライブラリです。ディープラーニングのアルゴリズムが多数実装されており、Googleの自社サービスでも活用されているとされています。
Keras
Kerasは、上記のTensorFlowなどのライブラリを利用しやすくするインターフェイスを提供しているラッパーです。TensorFlow以外にも、CNTKとTheanoを利用できます。 TensorFlowなどの機械学習用ライブラリは、自らアルゴリズムを実装することに比べれば、はるかに容易に機械学習を体験できますが、依然として専門知識を持たずに機械学習を試行するにはハードルが低いとは言えない状況でした。 Kerasは、より簡単に機械学習を利用することが可能となるようユーザーフレンドリーに設計されており、機械学習やプログラミングに詳しくなくとも容易に機械学習を行うことができます。 同様のラッパーは他にも複数ありますが、特に日本語のチュートリアルが整備されている点で使いやすいと言えます。
TensorFlowおよびKerasのインストール方法や仕組みの詳細は資料が豊富なため、他のドキュメントに解説を譲りたいと思います。
画像認識モデル
画像認識においては様々な研究がなされていますが、特に実績が多いCNN(Convolutional Neural Network)を利用してみたいと思います。CNNの技術的詳細は他のドキュメントを参照いただきたいと思いますが、概要は下記のとおりです。
CNN
CNNは、フィードフォワード型ニューラルネットワークのひとつで、全結合層を複数重ねた一般的な多層パーセプトロンとは異なり、畳み込み層(Convolution Layer)とプーリング層(Pooling Layer)を重ねた構造をとります。
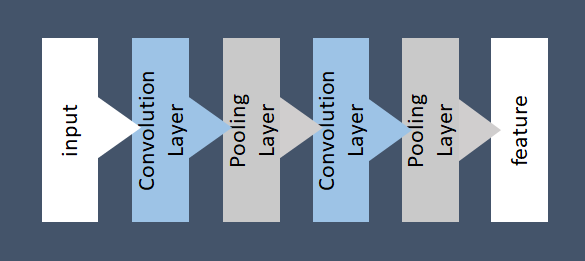
畳み込み層
画像から特徴を抽出するための層です。 画像を識別するには、ここに着目するとよい、という特徴があります。例えば、〇×判定を行う例では、〇はカーブにその特徴がよく表れ、×は真ん中のクロス部分や斜線部に特徴がでます。この特徴が画像のどこに現れるかわからないため、CNNでは特徴を抽出するためのフィルタを画像全体に対してスライドさせながら適用させていきます。 これによって画像全体から特徴的な情報を抽出していきます。
プーリング層
特徴として重要な情報を残しつつ画像を縮小して圧縮することで、微小な位置変化に対して頑強性を上げようとする層です。 例えば、手書き文字画像を認識しようと考えた場合、文字をどのあたりに書くかは様々です。左上の方に書くケースも右下の方に書くケースもあります。このように画像認識では、判別対象の画像が少しズレていたり、傾いていたりということが往々にしてあります。生物の脳では、位置変化が発生していても特徴を適切に捉えることができますが、コンピューターで画像を処理する場合、ピクセル単位で画像を取り扱う制約上、少しでも位置がズレていると異なる画像として認識されてしまいます。 このような位置変化に対する弱さを補う部分がプーリング層と呼ばれる階層です。
ファインチューニング
画像認識では、上記のような畳み込み層とプーリング層をどのように配置するか、各ニューロンの結合荷重などのモデルの構造が識別率に大きく影響を与えます。これらを試行錯誤や学習によって調整することで、できるだけ高い識別率を出せるようにします。ただし、これらの試行錯誤・学習は膨大な時間とマシンリソースを必要とします。
ある特定の分野で調整した画像認識用のモデルと、別の分野で調整したモデルとは、比較的似た構造となることが知られています。例えば、犬種を識別する画像認識モデルと、猫種を識別する画像認識モデルは似通った構造になります。
従って、ある問題を解決するために構築されたモデルを使いまわして再学習させると、一から学習させる膨大な時間と莫大な学習用サンプルデータを節約して、ある程度の精度を得ることができます。このように既にあるモデルを使いまわして、少ないデータセットで結合荷重を再調整することを「ファインチューニング」と呼びます。
ファインチューニングでは、画像認識コンペなどで優秀な成績であったモデルを利用して、結合荷重だけ再学習させる手法が良く取られます。
今回用意したモデル
今回は、ImageNetの1000クラス分類タスクを学習させたVGG-16モデルを再利用し、ファインチューニングを行いたいと思います。なお、VGG-16は2014年のILSVRCで提案された、畳み込み13層と全結合3層の合計16層(プーリング層はカウントしない)から構成されるCNNです。
KerasにはVGG-16モデルが標準で搭載されており、下記のように容易に利用可能です。
base_model = VGG16(weights='imagenet', include_top=False)
最後の層に全結合層を新たに追加し、合計17層とします。
x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(num_classes, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions)
活性化関数にはReLU(Rectified Linear Unit)を利用します。 追加した層のみを再学習対象とし、それ以外のVGG-16の全層は結合荷重を固定とします。
for layer in base_model.layers: layer.trainable = False
CNNでは、浅い層では縦線や横線などの大まかな特徴を抽出し、深い層(VGG-16の場合は15層以降)で、その画像特有の特徴を抽出する傾向がわかっています。そのため、効率よく再学習させることを目的として、浅い階層を固定しています。
鳥画像分類
鳥の画像(カラス、フラミンゴ、白鳥)の3クラスの識別を実施しました。
サンプル画像
Google画像検索から各クラスの画像を収集し、非写実的なイラスト画像、アルビノおよび雛の個体の画像を削除しました。今回は各クラスに下記の件数のサンプルを用意しています。
- カラス:649
- フラミンゴ:537
- 白鳥:555
下記に収集した画像の例を示します。
これらの画像を、ランダムに学習用データと検証用データに分割します。今回は、検証データを全体の20%としています。下記のようにscikit-learnのtrain_test_splitを利用することで、データの分割が可能です。
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.20)
画像のサイズは、そのままでは扱いにくいため、224x224ピクセルに圧縮・伸張して使用します。
学習結果
訓練回数(エポック:epoch)を50とした場合、学習過程は下記のようになりました。
Train on 1392 samples, validate on 349 samples
Epoch 1/50
1392/1392 [==============================] - 417s 300ms/step - loss: 1.0683 - acc: 0.4619 - val_loss: 1.0148 - val_acc: 0.6103
...(省略)
Epoch 50/50
1392/1392 [==============================] - 376s 270ms/step - loss: 0.3124 - acc: 0.8858 - val_loss: 0.3279 - val_acc: 0.8797
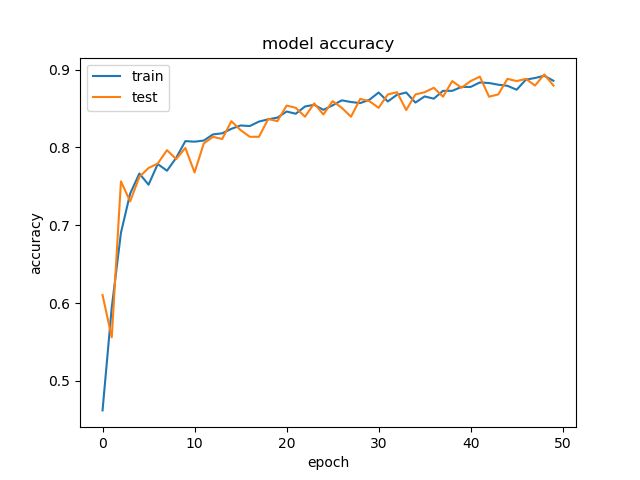
全エポックの学習を完了させるのにかかった時間は、通常のデスクトップ端末でCPUを利用し、5時間ほどでした。最終的には88%ほどの識別率となっているため、学習用のサンプル数と学習時間の割に高精度で分類できていると言えます。
偽装アイコンの検出
マルウェアの検出手法として、アイコン画像に着目する研究が一定の成果を上げています。
Pedro Silva, "Improving Malware Detection Accuracy by Extracting Icon Information", 10 Dec 2017, (https://arxiv.org/pdf/1712.03483.pdf).
上記は機械学習でクラスタリングを行う手法が提案されています。ただし、CNNといった画像認識の技術は使っていません。
Joe Security's Blog, 09.04.2014, (https://www.joesecurity.org/blog/7018452573408132310).
上記ブログの記事では「dHash」と呼ばれるハッシュアルゴリズムを開発し、正規アプリケーションのアイコン画像との比較によって検出を試みています。
また、マルウェアの実行ファイルを画像化し、機械学習による画像認識によって識別する手法が提案されています。
Lakshmanan Nataraj, Vinod Yegneswaran, Phil Porras, Jian Zhang, "A Comparative Assessment of Malware Classification using Binary Texture Analysis and Dynamic Analysis", Workshop on Artificial Intelligence and Security (AISec), Chicago, Oct. 2011, (https://vision.ece.ucsb.edu/sites/vision.ece.ucsb.edu/files/publications/aisec17-nataraj.pdf).
Vineeth S. Bhaskara, Debanjan Bhattacharyya, "Emulating malware authors for proactive protection using GANs over a distributed image visualization of dynamic file behavior", 30 Jul 2018, (https://arxiv.org/abs/1807.07525).
FFRIでも2016年3月に、アイコン画像を機械学習させ、マルウェア検出のための一観点とする下記の特許を取得しています。
- 特許名:「情報処理装置、情報処理方法、プログラム及びプログラムを記録したコンピュータ読み取り可能な記録媒体」
- 出願番号:特願2016-46762 (2016/03/10)
偽装アイコンに着目する理由
本稿では、実行ファイルを文書やフォルダなどに見えるように細工したアイコンを「偽装アイコン」と呼びます。下記のような利点から、偽装アイコンをマルウェア検出のための手掛かりとすることは有用であると考えられます。
悪意の存否が明確
一般的に、プログラムの不正らしさや悪意を定義することは容易ではありません。例えば、コードインジェクションを行うプログラムは、割合としてはマルウェアである率が高いですが、必ずしも悪意があるとは限らず、正常な検査用プログラムなども同様の技術を利用しています。 一方、アイコンを偽装して実行ファイルを文書やフォルダに見せかけている状況は、悪意があると判断して差し支えないと言えます。
機械的処理の効率
画像認識は機械的な処理でありながら、高い識別率を確立してきており、アイコン画像のように制限の大きな画像においては、より高い効果が期待できます。
今回は、先ほどと同じようにImageNetで学習済みのVGG-16モデルをアイコン画像でファインチューニングし、偽装アイコン画像をどの程度判別できるか簡易的に確認しました。
サンプルデータ
MS Wordの文書ファイルを装ったアイコンを有するマルウェアおよび、正常なプログラムから取得したアイコン画像を収集しました。クラスごとに下記の件数のサンプルを用意しています。
- Word文書偽装アイコン画像:437件
- その他アイコン画像:450件
下記に収集した画像の例を示します。

これらの画像を、先ほどと同じように、検証データを全体の20%となるよう分割します。
今回収集した画像ファイルは、あまり多いと言えないことから、元画像を回転させたり、ぼやかしたりして水増し(Data Augmentation)を行いました。Kerasでは下記のようにImageDataGeneratorを利用することで水増しが可能です。
datagen = ImageDataGenerator(
rotation_range = 0., # ランダム回転の回転範囲(0-180)
width_shift_range = 0., # ランダム水平シフトの範囲
height_shift_range = 0., # ランダム垂直シフトの範囲
shear_range = 0.2, # シアー強度
zoom_range = 0.2, # ランダムにズームする範囲
horizontal_flip = True, # 水平方向に入力をランダムに反転
vertical_flip = True, # 垂直方向に入力をランダムに反転
rescale = 1.0 / 255, # 与えられた値をデータに積算する
fill_mode = 'nearest' )
また、画像のサイズは50x50に圧縮・伸張して利用します。
識別結果
エポックを50とした場合、学習過程は下記のようになりました。
Epoch 1/50 22/22 [==============================] - 9s 422ms/step - loss: 0.7137 - acc: 0.5203 - val_loss: 0.6923 - val_acc: 0.5281 ... Epoch 50/50 709/709 [==============================] - 9s 13ms/step - loss: 0.0584 - acc: 0.9817 - val_loss: 0.1411 - val_acc: 0.9551
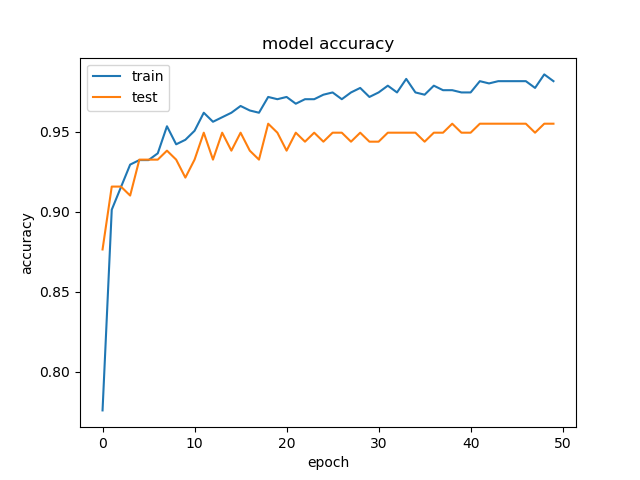
学習に要した時間は、同じ環境で30分ほどでした。最終的には95%ほどの識別率となっているため、かなり高精度で分類できていると言えます。
考察
結果は非常に高い識別率となりましたが、下記のような理由によるものと考えられます。
- 偽装アイコン画像はズレや劣化はあるものの、全体的に似た画像になる傾向があるため、比較的似た画像が学習データと検証データに分散した可能性がある
- 一般画像に比べて次元が低いため、識別しやすく、全体的に精度が高い可能性がある
また、実用的な検知方法としてはWordアイコン画像かそれ以外のアイコン画像かの2クラス分類ではなく、より多くの要素を考える必要があります。例えば、Excel、PDF、フォルダや画像など、様々な偽装方法が考えられるため、他クラス分類となります。そのため、識別精度は今回の実験より低下する可能性あります。
おわりに
今回はKerasを使って画像認識を行いました。 本稿で記載したように、Kerasを利用すると容易にディープラーニングの世界を覗いてみることができます。ファインチューニングやReLU、Data Augmentationなどの技術が開発され、特別に高性能なハードウェアや膨大な学習データがなくともある程度の識別率を持つ画像識別機が作成できるようになってきています。今後はさらに、機械学習の裾野が広がっていきそうです。