
はじめに
基礎技術研究部リサーチエンジニアの末吉です。
HTTP リクエストスマグリング(HTTP Request Smuggling: HRS)の CVE 登録数を見ると、最初に発表された 2005 年に大量に登録されて以降は下火傾向で、2018 年までは毎年数件ずつ登録される程度でした*1。 ところが 2019 年から再燃し、今年に至るまで再び大量に登録されだしています。
上記は CVE の登録数だけを見た傾向ですが、実際 HTTP リクエストスマグリングは 2019 年を境に急激に発展し、今年に至るまで毎年様々な新手法が発表され、注目を浴びています。
ただ、その割には日本語で HTTP リクエストスマグリングを扱った記事は少なく、この名前を聞いたこともないという方もそこそこ多いと思います。
そこで、この記事では HTTP リクエストスマグリングの基礎から Black Hat USA で発表された最新の研究内容まで一気通貫で解説します。
HTTP リクエストスマグリングは既に知っているから最新の研究内容だけ知りたいという方は Black Hat USA 2019 の HTTP Desync Attacks まで飛ばしてください。
なお、HTTP/1.1 のメッセージフォーマットやデータの渡し方などは既知のものとしてここでは説明しません。 また、RFC の一部を意訳していますが、正確性は保証しません。必要に応じて原文を参照してください。
- はじめに
- 頻出 RFC 用語
- HTTP リクエストスマグリング
- RFC の観点から見たここまでのまとめ
- 2019 年: HTTP Desync Attacks: Smashing into the Cell Next Door
- 2020 年: HTTP Request Smuggling in 2020 - New Variants, New Defenses and New Challenges
- 2021 年: HTTP/2: The Sequel is Always Worse
- 2022 年: Browser-Powered Desync Attacks: A New Frontier in HTTP Request Smuggling
- おわりに
- エンジニア募集
頻出 RFC 用語
HTTP の RFC で登場する用語のうち、この記事内で頻出する用語をここで簡単に説明します。必要に応じて参照してください。
- message: メッセージ。HTTP 通信における基本単位
- sender/recipient: 送信者/受信者。特定のメッセージを送信/受信する実装を指す
- client/server: クライアント/サーバー。これらのプログラムが特定の接続に対して実行する役割のみを指す。同じプログラムがクライアントとサーバー両方掛け持つこともある(プロキシサーバーなど)
- upstream/downstream: 上流/下流。メッセージが流れる方向を説明するための用語。すべてのメッセージは上流(upstream)から下流(downstream)へ送られる
- message-body: メッセージボディ。Transfer-Encoding が適用されている場合にのみ、メッセージボディとエンティティボディは異なる
- entity-body: エンティティボディ。メッセージボディそのままか、メッセージボディを Transfer-Encoding ヘッダーにしたがってエンコードしたもの。つまりは HTTP リクエストやレスポンスに付属する HTTP ボディのこと。RFC 2616 で使用される用語
HTTP リクエストスマグリング
HTTP リクエストスマグリングは、 2005 年に Watchfire のホワイトペーパー HTTP Request Smugglingで発表されました。
まず、クライアントがウェブサーバーに接続する例を考えます。 HTTP 通信を行うために構成されるデバイス(以下、HTTP デバイス)の一番単純な例は、以下のようなクライアント(ブラウザーなど)とウェブサーバーのみの構成です。
クライアント->ウェブサーバー
イントラネットなどの小規模なものを除くと、多くの場合はこの間に何かしらクライアント側、サーバー側でそれぞれ他の HTTP デバイスが存在します。 例えば、ウェブアプリケーションファイアウォール(WAF)、キャッシュサーバー、プロキシサーバー、ロードバランサーなどです。
これらは上流(メッセージが送信されてきた方向)から来た HTTP リクエストを処理し、下流(メッセージを送信する方向)に転送します。
次に、間にプロキシサーバーが入る構成を考えます。
クライアント->プロキシサーバー->ウェブサーバー
このプロキシサーバーは、速度向上のために異なるユーザー間でコネクションを共有する機能を持っています。 つまり、複数のクライアントがある場合に、プロキシサーバーとウェブサーバー間に張られる 1 つのコネクションを複数のクライアントが共有します。
さて、この時、プロキシサーバーとウェブサーバーで HTTP リクエストの解釈方法が異なっていたらどうなるでしょうか?
Transfer-Encoding と Content-Length の混在
以下のような HTTP リクエスト R を考えます。
R:
POST /index.html HTTP/1.1 Host: example.com Transfer-Encoding: chunked Content-Length: 6 0 G
HTTP リクエストの構造は RFC 9112 で定義されていますが、ここではホワイトペーパーが発表された 2005 年にあわせて当時最新版の RFC2616 を用いて説明します。 なお、現在最新版の RFC にはスマグリングに関する記述が追記されています。これは後述します。
Transfer-Encoding は、ボディの転送方式を指定する方式です。
Transfer-Encoding: chunked とすると、ボディは以下のように バイト長(16進数)->データ の流れを繰り返します。
最後はバイト長 0 と空行で終わります。
POST / HTTP/1.1 Host: example.com Content-Type: text/plain Transfer-Encoding: chunked a ABCDEabcde 5 hello 0
Content-Length は、ボディのバイト数を指定します。 Content-Length: 10 なら、ボディが 10 バイトあることを意味します。
POST /index.html HTTP/1.1 Host: example.com Content-Length: 10 ABCDEabcde
この 2 つのヘッダーの役割は重複しています。1 つのリクエストに両方設定されている場合、HTTP デバイスはどちらを採用すれば良いかわかりません。
これは RFC 2616 の 4.4 を読むと解決します。
3.If a Content-Length header field (section 14.13) is present, its decimal value in OCTETs represents both the entity-length and the transfer-length. The Content-Length header field MUST NOT be sent if these two lengths are different (i.e., if a Transfer-Encoding header field is present). If a message is received with both a Transfer-Encoding header field and a Content-Length header field, the latter MUST be ignored.
要約すると、「Transfer-Encoding と Content-Length が混在するものを受信した場合、後者(Content-Length)は無視する」ということです。 つまり、混在している場合は Transfer-Encoding を優先すると RFC で決まっています。 そのため、リクエスト R を受信した場合は、以下のように 2 つのリクエスト R1 と R2 として認識するのが正しい実装です。
R1:
POST /index.html HTTP/1.1 Host: example.com Transfer-Encoding: chunked Content-Length: 6 0
R2:
G
しかし、これはあくまでも RFC ではそう書いてあるという話です。実際のプログラムの実装ではありません。 すべての HTTP デバイスがちゃんとこの通りに実装されていれば良いのですが、開発者がこの仕様を知らなかったり、知っていても誤って実装してしまい、RFC に違反した実装の HTTP デバイスが生まれることがあります。 Content-Length を優先してしまう HTTP デバイスが上記リクエストを処理した場合、そのまま 1 つのリクエストとして処理します*2。
POST /index.html HTTP/1.1 Host: example.com Transfer-Encoding: chunked Content-Length: 6 0 G
さて、前述のネットワーク構成において、プロキシサーバーが RFC 違反の実装になっていて、上記例のように Content-Length を優先してしまう実装であるとします。 一方ウェブサーバーは RFC 通りに実装されていて、Transfer-Encoding を優先する実装であるとします。 また、攻撃者クライアント A および被害者クライアント B がプロキシサーバーに接続して、プロキシ経由でウェブサーバーにアクセスするとします。
この状態で A が B を攻撃する流れを見てみましょう。
まず、攻撃者クライアント A がプロキシサーバーに攻撃リクエスト R を送信します。プロキシサーバーはリクエスト R を受信すると、1 つのリクエスト R が来たと認識(誤解)し、ウェブサーバーにリクエストを転送します。
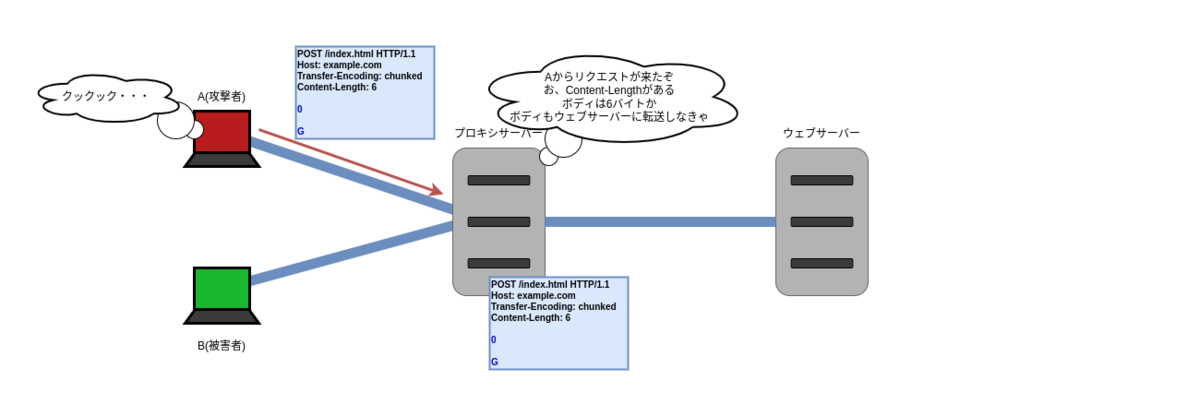
対してウェブサーバーは 2 つのリクエスト R1, R2 が来たと認識します。R1 は終端まである完全なリクエストなので、R1 に対応するレスポンス S1 をプロキシサーバーに返します。

プロキシサーバーは返ってきたレスポンス S1 を R に対応するレスポンスだとみなし、A に返します。
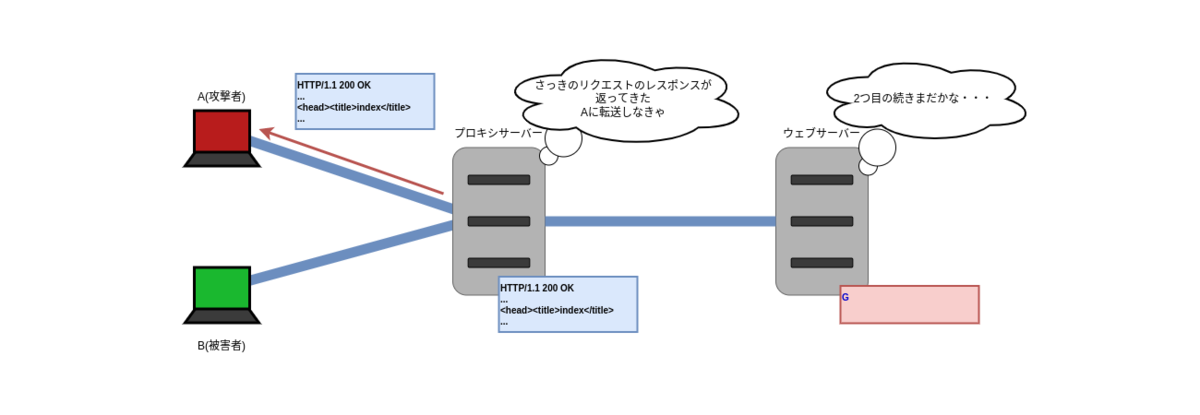
この時点で R2 は終端の無い不完全なリクエストなので、ウェブサーバーはプロキシサーバーから R2 の続きが来るのを待機している状態になっています。
ここで、被害者クライアント B が hello.html を取得するリクエスト R' (これはちゃんと終端のある普通のリクエスト)をプロキシサーバーに送信します。
R':
GET /hello.html HTTP/1.1 Host: example.com
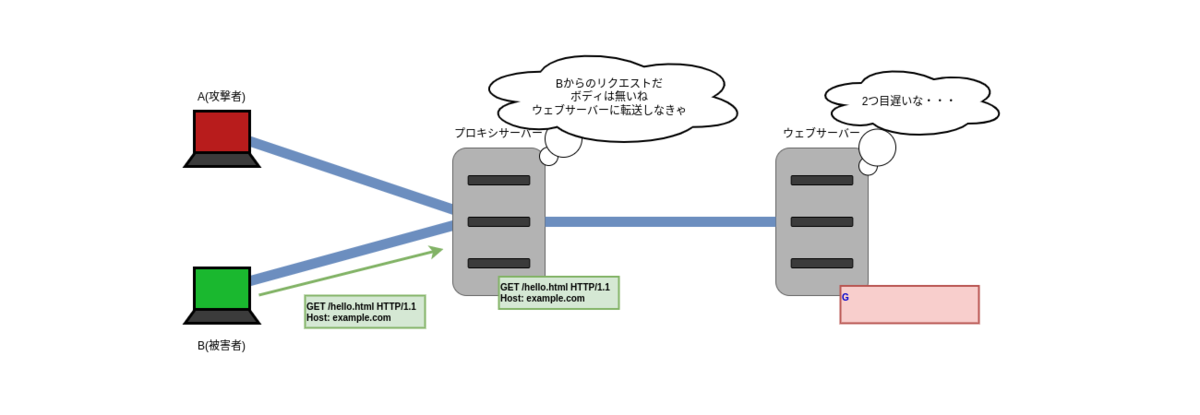
プロキシサーバーはそれをウェブサーバーに転送します。このプロキシサーバーは他のクライアントで使ったコネクションを使い回すので、B のリクエストは A のリクエストと同じコネクションで送信します。 すると、ウェブサーバーは R' が R2 の続きであると認識(誤解)し、R2 と R' を結合したリクエスト R2' と認識します。
R2':
GGET /hello.html HTTP/1.1 Host: example.com
R2' はメソッド名に R2 の余計な文字列がついてしまい、不正なメソッド名 GGET になってしまっています。
ウェブサーバーが RFC 2616 の 5.1.1 に従っていれば、501 Not Implemented が入ったレスポンス S2 をプロキシサーバーに返します。
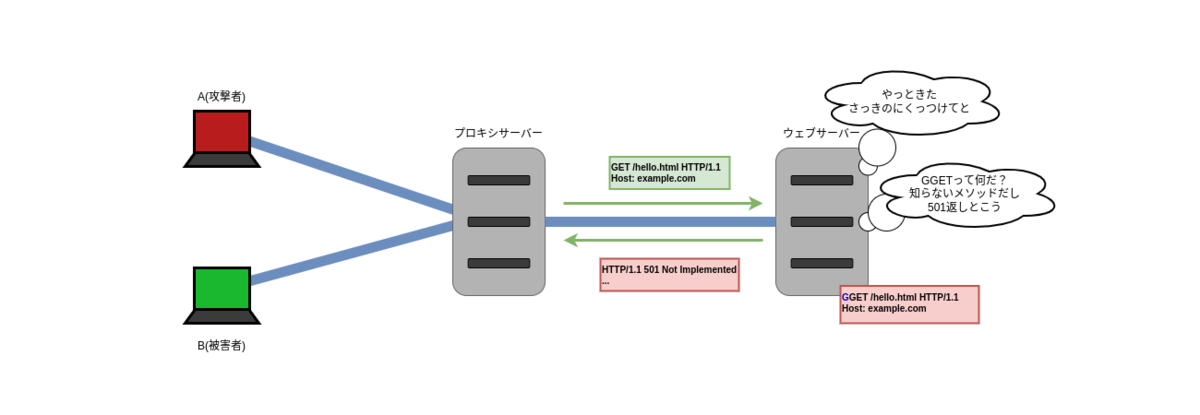
プロキシサーバーは、S2 を R' のレスポンスであると認識して B に返します。
ということで、攻撃リクエスト R の次にリクエスト R' を送信した B は、hello.html の情報を受け取ることができませんでした。 これは可用性の侵害に当たります。 上記の例では 501 が返るだけでしたが、R' の前に任意のリクエスト文を追記することで、R' を攻撃者の意図したリクエストに改ざんできます。 その結果セッションハイジャック攻撃を受けたり、ウェブサーバーのアプリケーションにクロスサイトスクリプティング(XSS)脆弱性があれば、それが反射型 XSS や Self-XSS であっても誘導無しに B を攻撃できます。
このように、介在する HTTP デバイスの挙動の不一致(Desync)を利用することで、もう一方の HTTP デバイスに気付かれることなく HTTP リクエストを「密輸(Smuggling)」*3できます。 被害者 B は知らないうちに運び屋にされ、密輸されたリクエストは B が送信したリクエストの一部として処理されます。 これが HTTP リクエストスマグリングです。
リクエストスマグリングは介在する HTTP デバイスによってできることが変化します。 そのため、前述した以外の攻撃に繋がることもあります。
キャッシュサーバーの場合、キャッシュを汚染(キャッシュポイズニング)できます。
WAF の場合、WAF にリクエストを誤解させることで、バイパスできます。 WAF の中にはスマグリングを検知するルールを持っているものもありますが、WAF そのものがスマグリングに脆弱な場合もあります。
上記で示した例の被害者は、攻撃リクエストの処理直後にリクエストを送信したクライアントです。
ウェブサーバーに密輸されたリクエストは直後に送信されたリクエストにくっつき、その時点で密輸したリクエストは消費され、以降のリクエストは改ざんされません。
そのため、被害者は 1 人(1 リクエスト)だけになります。 キャッシュポイズニングの場合は汚染されたキャッシュへのリクエストを送信したクライアント全員が被害者になり得ます。
RFC の修正
この挙動について 2014 年 6 月公開の RFC 7230 の 3.3.3 (廃止済み)では以下の文言に変更されています。
If a message is received with both a Transfer-Encoding and a Content-Length header field, the Transfer-Encoding overrides the Content-Length. Such a message might indicate an attempt to perform request smuggling (Section 9.5) or response splitting (Section 9.4) and ought to be handled as an error. A sender MUST remove the received Content-Length field prior to forwarding such a message downstream.
(意訳)
Transfer-Encoding と Content-Length が混在する場合、Content-Length を上書きする。 このようなメッセージはリクエストスマグリングかレスポンス分割攻撃をしようとしている可能性があるため、エラーとして処理するべきである。 送信者はこのようなメッセージを下流に転送する前に、受信した Content-Length ヘッダーを削除しなければならない。
7230 ではスマグリングに対する言及が追加されました。 混在メッセージをエラーとして処理するかどうかは「ought to」なので、強制ではありません。 しかし、「送信者は転送前に Content-Length ヘッダーを削除しなければならない」など、より厳密な要件が追記されています。
ここでいう送信者は上記構成でいうならば、クライアントというよりは間に入っているプロキシサーバーがウェブサーバーに向けてリクエストを転送する機能を指します。 クライアントは攻撃者なので、この要件を無視して Transfer-Encoding と Content-Length の混在リクエストを送信してきます。
送信者(上記例の場合プロキシサーバー)は混在リクエストを受信したとき、エラーを返さないとしたら下流(上記例の場合ウェブサーバー)に転送するわけですが、その前に Content-Length を削除しなければなりません。 こうすることで、プロキシサーバーではなくウェブサーバーが Content-Length 優先実装になっていたとしても、スマグリングできなくなります。
このように、下流が RFC 違反していても脆弱性が発現しないようにする緩和策が追記されています。 RFC 違反しているデバイスが悪いというだけで片付けるのではなく、緩和策を追記している点がとても素晴らしいですね。
最新版の RFC 9112 の 6.3 では、以下の文言に変更されています。
If a message is received with both a Transfer-Encoding and a Content-Length header field, the Transfer-Encoding overrides the Content-Length. Such a message might indicate an attempt to perform request smuggling (Section 11.2) or response splitting (Section 11.1) and ought to be handled as an error. An intermediary that chooses to forward the message MUST first remove the received Content-Length field and process the Transfer-Encoding (as described below) prior to forwarding the message downstream.
(変更点の意訳)
(混在メッセージを)エラーにせず下流に転送する場合、まず Content-Length ヘッダーを削除してから、Transfer-Encoding を処理しなければならない。
内容自体は変化していませんが、記述が少しだけ詳しくなっています。
複数の Content-Length
RFC 2616 の 4.2 では、以下のように書いてあります。
Multiple message-header fields with the same field-name MAY be present in a message if and only if the entire field-value for that header field is defined as a comma-separated list [i.e., #(values)]. It MUST be possible to combine the multiple header fields into one "field-name: field-value" pair, without changing the semantics of the message, by appending each subsequent field-value to the first, each separated by a comma. The order in which header fields with the same field-name are received is therefore significant to the interpretation of the combined field value, and thus a proxy MUST NOT change the order of these field values when a message is forwarded.
(意訳)
同じフィールド名を持つ複数のメッセージヘッダーフィールドは、フィールド値全体がカンマ区切りのリストとして定義されている場合に限り存在してもよい。 最初のフィールド値に、カンマ区切りで後続のフィールド値を追加することで、メッセージのセマンティクスを変えずに複数のヘッダーフィールドを 1 つの "field-name: field-value" の組にまとめることが可能でなければならない。 ヘッダーフィールド名の順序は重要である。プロキシは転送時にこの順序を変更してはならない。
同じフィールド名のヘッダーを複数リクエストに含められるかは、文法で定められています。 例えば Accept-Encoding の文法は以下の通りです。
Accept-Encoding = "Accept-Encoding" ":"
1#( codings [ ";" "q" "=" qvalue ] )
codings = ( content-coding | "*" )
# がカンマ区切りのリストを意味します。
複数の同名のヘッダーフィールドは、単一のフィールド名のカンマ区切りのリストとしてまとめることができます。
そのため、以下は同じです。
Accept-Encoding: compress Accept-Encoding: gzip
Accept-Encoding: compress, gzip
さて、以下のヘッダーを持つリクエストを考えます。
Content-Length: 0 Content-Length: 44
このリクエストには Content-Length ヘッダーが 2 つついています。
1 つのリクエストにボディが 2 つ以上存在することはありませんので、Content-Length が 2 つ含まれることも普通ありません。
また、Content-Length の文法は以下の通りなので、複数持つことは許可されていません。
Content-Length = "Content-Length" ":" 1*DIGIT
ですが、RFC 2616 ではこのときの対処法は明確には言及されていません(後述)。 そのため、以下のどれを採っても 2616 的には問題ありません。
- リクエストを不正なものとみなしてエラーを返す
- 1 つ目の
Content-Lengthを採用する - 2 つ目の
Content-Lengthを採用する
この曖昧さによって挙動の不一致が起こり、結果として HTTP リクエストスマグリングが発生します。
厄介なことにどの実装でも RFC 的には問題がないため、この場合はただどちらを直せばいいという話だけでは収まりません。 さらに、HTTP デバイス単体のレビューやテストでは挙動の不一致に気付けません。 そのため RFC 違反以上に実装が混在し、不一致が生じやすくなります。
RFC の修正
このことを受け、 RFC 7230 の 3.3.2 ではこれに関する記述が追記されました。
If a message is received that has multiple Content-Length header fields with field-values consisting of the same decimal value, or a single Content-Length header field with a field value containing a list of identical decimal values (e.g., "Content-Length: 42, 42"), indicating that duplicate Content-Length header fields have been generated or combined by an upstream message processor, then the recipient MUST either reject the message as invalid or replace the duplicated field-values with a single valid Content-Length field containing that decimal value prior to determining the message body length or forwarding the message.
(意訳)
上流から
Content-Lengthが複数存在するものを受信した場合は、無効なメッセージとして扱うか、転送する前にどれか一つを採用して単一の正しい形のContent-Lengthヘッダーに変換しなければならない。
不正な形式としてエラーを返すか、エラーにしなくても Content-Length をどれか選んでその値に統一してから下流に転送するという 2 つから選べるようになっています。
後者の方法は RFC の後方互換性をなるべく壊さないよう意識した形と考えられます。
さらに RFC 9112 の 6.3 では以下の文言に変わりました。
- If a message is received without Transfer-Encoding and with an invalid Content-Length header field, then the message framing is invalid and the recipient MUST treat it as an unrecoverable error, unless the field value can be successfully parsed as a comma-separated list (Section 5.6.1 of [HTTP]), all values in the list are valid, and all values in the list are the same (in which case, the message is processed with that single value used as the Content-Length field value). If the unrecoverable error is in a request message, the server MUST respond with a 400 (Bad Request) status code and then close the connection. If it is in a response message received by a proxy, the proxy MUST close the connection to the server, discard the received response, and send a 502 (Bad Gateway) response to the client. If it is in a response message received by a user agent, the user agent MUST close the connection to the server and discard the received response.
(意訳)
Transfer-Encoding がなく無効な Content-Length ヘッダーフィールドが存在する場合、エラーとして扱わなければならない。 ただし、 Content-Length フィールド値がカンマ区切りリストであり、すべて同じ値で有効な場合は、単一の値として処理する。
以下のようなリクエストを考えます。
Content-Length: 42 Content-Length: 100
7230 ではどちらかを選び、選ばなかったほうを削除するという選択ができましたが、9112 ではこの場合は不正な形式として常にエラー(400 Bad Request)を返して接続を閉じなければならないと定められました。
ただし、以下のように複数設定されていても同一の正当な値である場合、これは 1 つの Content-Length: 42 として正当扱いします。
Content-Length: 42 Content-Length: 42
Content-Length: 42, 42
こうして、上記の通りに実装していないものは RFC 違反なので修正すべきと言えるようになりました。
ここまでで紹介した手法は Transfer-Encoding(TE) と Content-Length(CL) の組み合わせでした。
これらは HTTP リクエストスマグリングの基本形のようなもので、TE と CL の組み合わせは TE.CL または CL.TE, 2 つの CL の組み合わせは CL.CL と略されます。
この略称は以降も登場します。
ちなみに RFC9112 の 6.3 は全部で 8 個のルールがあり、1 番から順に優先して適用されます。 TE と複数の CL があるリクエストの場合、TE と CL の混在は 3 番、複数の CL は 5 番なので、TE が優先されます。 といっても複数の Content-Length は「Transfer-Encoding がなく」が条件なので、どちらにせよ当てはまりません。
GET メソッド + Content-Length
RFC 2616 の 4.3 には以下のように書いてあります。
The presence of a message-body in a request is signaled by the inclusion of a Content-Length or Transfer-Encoding header field in the request's message-headers. A message-body MUST NOT be included in a request if the specification of the request method (section 5.1.1) does not allow sending an entity-body in requests. A server SHOULD read and forward a message-body on any request; if the request method does not include defined semantics for an entity-body, then the message-body SHOULD be ignored when handling the request.
(意訳)
リクエストにメッセージボディが存在することは、リクエストのヘッダーに Content-Length または Transfer-Encoding ヘッダーフィールドを含めることで通知する。 リクエストメソッドの仕様でエンティティボディの送信が許可されていない場合、リクエストにメッセージボディを含めてはいけない。 サーバーは任意のリクエストでメッセージボディを読み取って転送すべきである。 ただし、リクエストメソッドに定義されたセマンティクスのエンティティボディが定義されていない場合、リクエストを処理するときにメッセージボディを無視すべきである。
例えば、GET メソッドはボディの送信について特別言及されていません。
ただし、 RFC 2616 の 9.3 に「GET メソッドは Request-URI によって識別される情報を取得することを意味する」と書いてあるので、ボディは決まった意味を持たず、URI 部分のみでデータをやり取りするメソッドと定められています。
ゆえに、前述の「リクエストメソッドに定義されたセマンティクスのエンティティボディ」は GET メソッドには存在しないので、GET メソッドでやってきたボディは無視すべき(SHOULD)です。 RFC における SHOULD は特別な理由が無ければそう実装すべきという推奨です。MUST のような強制ではありません。
GET / HTTP/1.1 ... Content-Length: 42 ...
というリクエストが来た時、Content-Length を解釈してボディを読み取るか、それとも Content-Length とボディを無視するかは自由です。 つまり、RFC 的に上記リクエストは 2 通りの解釈ができてしまい、スマグリングが発生します。
RFC の修正
RFC 7230 の 3.3 では、以下の文言に変更されています。
The presence of a message body in a request is signaled by a Content-Length or Transfer-Encoding header field. Request message framing is independent of method semantics, even if the method does not define any use for a message body.
(変更点の意訳)
リクエストメッセージのフレーミングはメソッドがメッセージボディの用途を定義していなくても、メソッドセマンティクスから独立している。
メッセージのフレーミングとは、ざっくり言ってしまうとメッセージの構造のことです。つまりこの文章は、「メソッドに関係なく Content-Length または Transfer-Encoding ヘッダーがあればボディが存在する」ことを意味しています。 これによって 2616 の SHOULD の曖昧さがなくなり、「GET でも POST でもボディの存在を示すヘッダーがあるならボディもちゃんとパースすること」と変更されました。
RFC 9112 の 6.1 では、内容は変わっていませんが表現が少し簡潔になっています(訳は省略)。
The presence of a message body in a request is signaled by a Content-Length or Transfer-Encoding header field. Request message framing is independent of method semantics.
文法違反のリクエスト
HTTP の RFC では拡張 BNF (ABNF)記法を使用してメッセージの文法を定義しています。
ヘッダーの文法は RFC 2616 の 4.2 に書いてあります。
message-header = field-name ":" [ field-value ]
field-name = token
field-value = *( field-content | LWS )
field-content = <the OCTETs making up the field-value
and consisting of either *TEXT or combinations
of token, separators, and quoted-string>
この文法によると、field-name(フィールド名)と : の間に空白は入れられません。
そのため、Content-Length : 4649 のようなものは空白が 1 文字入っているため文法違反です。
ですが、文法違反のリクエストが来たときの扱いは、実は RFC 2616 に明記されていません。
RFC 7230 の 2.5 では、以下のように書いてあります。
Unless noted otherwise, a recipient MAY attempt to recover a usable protocol element from an invalid construct. HTTP does not define specific error handling mechanisms except when they have a direct impact on security, since different applications of the protocol require different error handling strategies. For example, a Web browser might wish to transparently recover from a response where the Location header field doesn't parse according to the ABNF, whereas a systems control client might consider any form of error recovery to be dangerous.
(意訳)
明記されていない限り、受信者は不正な構成から使用可能なプロトコル要素の回復を試みることがある。 HTTP は直接セキュリティに関わる場合を除き、特定のエラーハンドリングについて定義していない。これはプロトコルのアプリケーション毎に異なるエラーハンドリング戦略が必要なためである。 例えば、ウェブブラウザーは Location ヘッダーフィールドが ABNF に従ってパースできないレスポンスを透過的に回復したいことがあるが、システム制御クライアントの場合はあらゆる形式のエラーを危険とみなすことがある。
つまり、「アプリケーション毎にこのエラーを寛容に受け入れるべきか回復不能とみなすべきかは異なるから、直接セキュリティに関わるものでなければ定義していない」ということです。 これは最新版の RFC 9110 でも同様です。 ちなみに、HTTP/2 の RFC 7540 では不正な形式のメッセージに対する扱いが明記されています。
そのため、このときエラーを返すか当該行を無視するか寛容に受け入れるかはデバイスによって異なり、その挙動の不一致によってスマグリングが可能になります。
RFC の修正
フィールド名と : の間の空白について、RFC 7230 の 3.2.4 では、以下の文言が追加されました。
No whitespace is allowed between the header field-name and colon. In the past, differences in the handling of such whitespace have led to security vulnerabilities in request routing and response handling. A server MUST reject any received request message that contains whitespace between a header field-name and colon with a response code of 400 (Bad Request). A proxy MUST remove any such whitespace from a response message before forwarding the message downstream.
(意訳)
ヘッダーフィールド名とコロンの間に空白を入れるのは許可されていない。 過去にはリクエスト/レスポンスをハンドルするときにこの空白の扱い方のせいでセキュリティ上の脆弱性を引き起こしたことがある。 サーバーはヘッダーフィールド名とコロンの間に空白が入っているリクエストを受信したら、400 (Bad Request)を返さなければならない。 プロキシはレスポンスメッセージにそのような空白が含まれていた場合、メッセージを下流に転送する前に削除しなければならない。
間に空白を入れたものが明確に禁止されるようになりました。 また、これ以外にもメッセージのパースについて、色々な注意点が追記されています。詳しくは原文を参照してください。
これは前述した「直接セキュリティに関わるもの」に当たるので、個別対応のような形で「このパターンのときは 400 を返すように」と追記されています。
大きすぎるリクエスト
RFC 2616 の 10.4.14 には以下のように書いてあります。
The server is refusing to process a request because the request entity is larger than the server is willing or able to process. The server MAY close the connection to prevent the client from continuing the request.
(意訳)
サーバーが処理できるサイズより大きいリクエストエンティティを拒否する場合、コネクションを閉じてクライアントのリクエストを閉じても良い。
処理できるサイズを超えるリクエストを受信した時、どのように扱うかは MAY であり、任意で決めて良いとなっています。 そのため、デバイスによってエラーを返したり、処理を続行しようとしたりと動作はまちまちです。 中には処理できるサイズを超えたらそこで一旦リクエストを終端させ、以降は次のリクエストとみなして受信するデバイスも存在します。 この場合、処理可能サイズを利用したスマグリングができます。
RFC の修正
RFC 7230 の 3.2.5 (最新版は RFC 9110 の 5.4 )では、以下の文言が追加されています。
HTTP does not place a predefined limit on the length of each header field or on the length of the header section as a whole, as described in Section 2.5. Various ad hoc limitations on individual header field length are found in practice, often depending on the specific field semantics. A server that receives a request header field, or set of fields, larger than it wishes to process MUST respond with an appropriate 4xx (Client Error) status code. Ignoring such header fields would increase the server's vulnerability to request smuggling attacks (Section 9.5). A client MAY discard or truncate received header fields that are larger than the client wishes to process if the field semantics are such that the dropped value(s) can be safely ignored without changing the message framing or response semantics.
(意訳)
HTTP は各ヘッダーフィールドの長さやヘッダーセクション全体の長さを事前定義していない。 だが、実際は特定のフィールドのセマンティクスに応じて個別に長さをアドホックに制限していることが多い。 サーバーが処理したいサイズまたは処理可能なサイズを超えるサイズのリクエストヘッダーフィールドまたはフィールド群をサーバーが受信した場合、適切な 4xx (クライアントエラー) を返さなくてはならない。 このようなヘッダーフィールドを無視すると、リクエストスマグリング攻撃に脆弱になる可能性が高くなる。 クライアントは処理したいサイズまたは処理可能なサイズを超えるレスポンスを受信したとき、メッセージのフレーミングやレスポンスのセマンティクスを変更せずに値を安全に切り落とせる場合は、ヘッダーフィールドを破棄したり途中で切り落としても良い。
処理可能サイズを超えるヘッダーフィールドが来た場合、サーバーは 4xx (クライアントエラー)を返さなければならない、と追記されました。 これによって、処理可能サイズを利用したスマグリングが困難になっています。
RFC の観点から見たここまでのまとめ
今までのスマグリング手法を RFC 記載の観点でまとめると、以下の 3 つに分類できます。
- RFC 記載あり: Transfer-Encoding + Content-Length など
- RFC 記載無し: 複数の Content-Length など
- RFC 選択可能: GET + Content-Length など
RFC 記載があるパターンの修正は簡単で、違反しているデバイスを修正するだけです。
RFC 無しはまずこれを RFC に含めるべきかの検討が必要になります。
RFC 選択可能は RFC に記載はありますが、どちらでも良いという曖昧さで起こったものであるため、これも RFC を修正すべきかの検討が必要になります。
ということで、スマグリングは単にそのデバイスにある脆弱性というだけで片付く問題でも無く、RFC に根付くこともある厄介な脆弱性であることがわかると思います。
複数の HTTP デバイスが絡んで発現する脆弱性なので、関与するすべての HTTP デバイスが RFC 違反していても挙動が一致さえしていれば、この脆弱性が発現しないことも厄介な点です。
ここまでで従来の HTTP リクエストスマグリングについて解説しました。
ここからは Black Hat USA 2019 〜 2022 で発表された最新の研究内容 4 つを紹介します。
2019 年: HTTP Desync Attacks: Smashing into the Cell Next Door
前述の通り、今までの HTTP リクエストスマグリングは正当な値の TE と CL を混在させる手法でした。 この手法が知られるにつれて多くの HTTP デバイスがこの脆弱性を修正して RFC も改訂され、新しく HTTP リクエストスマグリングを見つけるのは難しくなっていきました。 そしてこの脆弱性は風化した扱いを受け、話題になることも少なくなっていきました。
ところが、PortSwigger が 2019 年に HTTP Desync Attacks と名付けた新たなスマグリング手法を発表しました。 これは TE/CL の組み合わせであることは従来と同じですが、様々な細工を加えることで Transfer-Encoding 優先の挙動を狂わせ、挙動の不一致を起こせることを実証しました。
そしてこの発表で何よりインパクトが大きかったのは、もはや過去のものと思われていたスマグリング攻撃によって様々な有名ウェブサイトをハッキングし、深刻な被害を引き起こせることを証明した点です。 この発表によって HTTP リクエストスマグリングの恐怖が蘇りました。
新しいスマグリングパターン
この発表で提案された手法は、今までのことを理解できていれば非常に単純です。
Transfer-Encoding: chunked Transfer-Encoding: x
Transfer-Encoding: xchunked
Transfer-Encoding: xchunked (※ヘッダーフィールド名の先頭に空白がある)
などのように、Transfer-Encoding という名前かフィールド値に不正な文字を混ぜたり、不正なエンコーディング名を指定します。
この発表では Transfer-Encoding の難読化と呼ばれています。
今までは Transfer-Encoding と Content-Length の組み合わせは考慮されていましたが、不正なエンコーディング名を指定された場合のスマグリングは考慮されていませんでした。 これを利用して Transfer-Encoding ヘッダーを隠し、Content-Length を組み合わせることで Transfer-Encoding 優先という仕様を突き破って挙動の不一致を発生させることができます。
この方法が発表されると、多くのアプリケーションで脆弱性が発見され、修正されました。
実装の問題
このスマグリングパターンが可能になる背景について、少し立ち入ってみましょう。
文字列が chunked であることを比較するためにはどのような実装方法があるでしょうか。
通常は value == "chunked" のような感じで文字列が完全一致するか比較するはずです。
この場合、xchunked は chunked ではありませんので NG です。
しかし、中には value.contains("chunked") のような感じで、文字列の中に chunked が包含されていれば OK とするデバイスもあります*4。
この場合、xchunked は OK です。
この挙動の不一致でスマグリングを起こせます。
Content-Length: 5 Transfer-Encoding: xchunked
というヘッダーのリクエストを受信したとき、完全一致比較しているデバイスは xchunked を不正なエンコーディング名であるとみなして無視し、Content-Length を採用します。
包含比較しているデバイスは xchunked を正当なエンコーディング名 chunked であるとみなし、Transfer-Encoding を採用します。
このような実装の問題を突いたものが上記の一例です。
Transfer-Encoding の文法
RFC 7230 における Transfer-Encoding の文法は以下の通りです。
Transfer-Encoding = 1#transfer-coding
transfer-coding = "chunked" ; Section 4.1
/ "compress" ; Section 4.2.1
/ "deflate" ; Section 4.2.2
/ "gzip" ; Section 4.2.3
/ transfer-extension
transfer-extension = token *( OWS ";" OWS transfer-parameter )
transfer-parameter = token BWS "=" BWS ( token / quoted-string )
複数の Transfer-Encoding は許可されています。Transfer-Encoding: gzip, chunked のようにして gzip 圧縮とチャンクを組み合わせたりします。
transfer-extension という文法があり、その中では任意のトークン文字列を受け入れる仕様になっています。 Transfer-Encoding に指定できるパラメーターは Transfer Coding Registry と呼ばれるレジストリで RFC とは別に管理されています。 これに対応するため、Transfer-Encoding は任意のトークン文字列を受け入れられるようになっています。 ちなみにこの仕様は RFC 9112 でも同様です。
そのため、Transfer-Encoding: x も文法には準拠していますが、普通は不正なエンコーディング名と認識されます。
しかし、これをどう扱うかはデイバスの自由です。クライアントにエラーを返す場合もあれば、ただ無視するだけの場合もあります。
RFC の修正
2019 年当時最新版の RFC は 7230 です。
前述の通り、文法違反のメッセージの扱いは一部の例外を除いて明記されていません。 RFC 9112 の 2.2 では以下の文言が追記されました。
A recipient that receives whitespace between the start-line and the first header field MUST either reject the message as invalid or consume each whitespace-preceded line without further processing of it (i.e., ignore the entire line, along with any subsequent lines preceded by whitespace, until a properly formed header field is received or the header section is terminated). Rejection or removal of invalid whitespace-preceded lines is necessary to prevent their misinterpretation by downstream recipients that might be vulnerable to request smuggling (Section 11.2) or response splitting (Section 11.1) attacks.
(意訳)
スタートラインと最初のヘッダーフィールドの間に空白があるメッセージの受信者は、メッセージを無効として拒否するか、空白が先行する各行をそれ以上処理せずに消費しなければならない(つまり、適切に構成されたヘッダーフィールドが来るかヘッダーセクションが終了するまで行全体を無視し続ける)。 リクエストスマグリングまたはレスポンス分割攻撃に脆弱な下流の受信者が誤解しないように、無効な空白が先行する行は拒否するか削除する必要がある。
これにより Transfer-Encoding: chunked のような空白が先行するヘッダー名を弾けます。
2020 年: HTTP Request Smuggling in 2020 - New Variants, New Defenses and New Challenges
SafeBreach が発表したスマグリングパターンおよびスマグリング防御機構の話です。
新しいスマグリングパターンの一部を紹介します。
Content-Length abcde: 3のように、ヘッダー名末尾に余計な文字列を追加\rContent-Length: 39のように、ヘッダー名先頭に\r(復帰) を入れるContent-Length: +1234のように符号付き数値にするContent-Length: 12 34のように数値の間に空白を混ぜる
他に、WAF である ModSecurity の検知ルールを回避してスマグリングするパターンも説明されていますが、ここでは割愛します。
面白いのは符号付きの数値文字列を受け入れてしまう例です。 Content-Length の文法では、符号付き文字列は違反です。
このバグは Content-Length の数値文字列のパースに C 言語の atoi() や、Python の int() のような符号付き数値文字列を受け入れてしまう仕様の機能を使っていたために発生していたそうです。
確かに気を付けないと実装時に間違ってしまいそうなミスです。
防御機構 RSFW
この発表では Request Smuggling Firewall(RSFW) というリクエストスマグリング防御機構が OSS で公開されました。
WAF ではなく、スマグリング検知に特化した軽量なツールとしてサーバーに組み込めるように設計されています。 これは WAF のようなネットワークを変更するシステムを追加したくなかったからだそうです。
手法としては、ネットワーク通信関数をフックして HTTP 通信を監視し、以下を検証します。
- RFC 2616 にある形式の厳密な遵守
- リクエストライン
- ヘッダー名
- Content-Length, Transfer-Encoding の値
- ヘッダー改行
- チャンク形式のボディ
- デフォルト設定では遵守しないものは全て拒否
2021 年: HTTP/2: The Sequel is Always Worse
HTTP Desync Attacks の続編で、HTTP/2 デバイスでスマグリングする手法を示したのがこの発表です。 話自体は単純で、HTTP/2 ではスマグリングできないので、プロキシが持つ HTTP/1.1 にダウングレードする機能を利用してスマグリングします。
HTTP/2 は 2015 年 5 月に RFC 7540 が出てからまだ 7 年しか経っていません。 HTTP/1.1 と比較すればまだまだ若い存在で、普及率も 2021 年の頭には 50% を超えたそうですが、それでもまだ HTTP/1.1 ほどではありません。
そのため、HTTP/2 をサポートするプロキシの多くは HTTP/2 のパケットを HTTP/1.1 にダウングレードする機能を持っていて、HTTP/2 に対応していないウェブサーバーとも通信できる機能を備えています。
ただ、HTTP/2 は HTTP/1.1 のような互換性のしがらみが無く、技術の進歩もあって大幅にセキュリティ面も改善されています。 ゆえにダウングレードするということは、セキュリティの弱体化を意味する場合があります。 このダウングレード機能を利用したのがこの発表です。
まずは HTTP/2 の構造を簡単に説明します。既に知っている方は HTTP/2 Desync まで飛ばしてください。
HTTP/2 の構造
HTTP/2 は現在は 2022 年 6 月公開の RFC 9113で定義されていますが、ここでは発表当時最新版の RFC 7540 (廃止済み)で説明します。
HTTP/1.1 と HTTP/2 の主な違いは以下の 3 つです。
- バイナリベース
- 疑似ヘッダー
- フレーム単位での送信
バイナリベース
HTTP/1.1 のメッセージはテキストベースでしたが、HTTP/2 はバイナリベースです。ヘッダーの圧縮などを行うことで、1.1 と比べて転送効率が向上しています。
疑似ヘッダー
HTTP/2 ではメソッド名や URI などを疑似ヘッダーと呼ばれる疑似的なヘッダーとして扱います。 これは HTTP ヘッダーとは異なるため、ウェブサーバーなどはこれを HTTP ヘッダーとして扱ってはなりません。
前述の通り HTTP/2 はバイナリベースです。そのため、HTTP/2 のメッセージを表現するときは、人間が読める表現に直します。
:method GET :scheme http :authority example.com :path / foo bar
疑似ヘッダーは : から始まります。
疑似ヘッダーは RFC で定義されているもの以外を使用してはなりません。
: から始まらないヘッダー(上記例でいえば foo) は普通の HTTP ヘッダーとして扱います。
疑似ヘッダーは必ず HTTP ヘッダーより前に存在しなくてはなりません。HTTP ヘッダーの後に疑似ヘッダーが存在する場合は不正な形式のメッセージとして扱います。
HTTP/2 ではヘッダー名は全て小文字で表します。大文字がヘッダー名に含まれていれば、不正な形式のメッセージとして扱われます。
HTTP/1.1 ではヘッダー名と値の間に : が入っていましたが、HTTP/2 では半角空白のみで名前と値を分けています。
HTTP/2 はバイナリベースなので、 HTTP/1.1 と異なり、ヘッダー名には大文字以外であればどの文字でも入れられます。 ただしこれは、RFC 7540 では言及されていないというだけです。最新版の RFC 9113 の 8.2 では禁止文字が定められています。
上記のリクエストは、 HTTP/1.1 でいえば以下のリクエストにあたります。
GET / HTTP/1.1 Host: example.com Foo: bar
フレーム
HTTP/2 ではフレームと呼ばれる単位でデータを送信します。
今回重要なのは HEADERS フレームと DATA フレームです。 名前の通り、ヘッダーをやり取りするためのフレームとデータをやり取りするためのフレームです。
HTTP/1.1 ではリクエストラインから CRLF 区切りでヘッダーを記述し、CRLF を 2 つ挟んでボディを記述するという方式でしたが、HTTP/2 ではヘッダーは HEADERS フレーム、ボディは DATA フレームに入れるという形で分けられています。
フレームのサイズは決まっていて、16KB 〜 8MB です。 範囲外のサイズのフレームを受信した場合、エラー(FRAME_SIZE_ERROR)を返さなければなりません。
例えば、POST メソッドでデータ abcd を送信する場合、以下のようにフレームを分けます。
HTTP/2 には Content-Length も Transfer-Encoding も存在しませんが、代わりに content-length (全て小文字)ヘッダーフィールドが用意されています。
これは Content-Length と同じで、ボディのバイト数を指定します。
HEADERS フレーム:
:method POST :path /data.php :authority example.com content-length 4
DATA フレーム:
abcd
これを HTTP/1.1 で表すと、以下のようなリクエストになります。
POST /n HTTP/1.1 Host: example.com Content-Length: 4 abcd
content-length の扱いは RFC 7540 の 8.1.2.6 に書いてあります。
A malformed request or response is one that is an otherwise valid sequence of HTTP/2 frames but is invalid due to the presence of extraneous frames, prohibited header fields, the absence of mandatory header fields, or the inclusion of uppercase header field names.
A request or response that includes a payload body can include a content-length header field. A request or response is also malformed if the value of a content-length header field does not equal the sum of the DATA frame payload lengths that form the body. A response that is defined to have no payload, as described in [RFC7230], Section 3.3.2, can have a non-zero content-length header field, even though no content is included in DATA frames.
Intermediaries that process HTTP requests or responses (i.e., any intermediary not acting as a tunnel) MUST NOT forward a malformed request or response. Malformed requests or responses that are detected MUST be treated as a stream error (Section 5.4.2) of type PROTOCOL_ERROR.
For malformed requests, a server MAY send an HTTP response prior to closing or resetting the stream. Clients MUST NOT accept a malformed response. Note that these requirements are intended to protect against several types of common attacks against HTTP; they are deliberately strict because being permissive can expose implementations to these vulnerabilities.
(意訳)
不正な形式のリクエストまたはレスポンスとは、それ以外は妥当だが、無関係なフレームの存在、禁止されているヘッダーフィールド、必須ヘッダーフィールドの欠如、または大文字を含むヘッダーフィールド名があるために無効なものを指す。
ペイロードボディを含むリクエストまたはレスポンスには content-length ヘッダーフィールドを含めることができる。 content-length ヘッダーフィールドの値が DATA フレームのペイロードの長さの合計と一致しないリクエストまたはレスポンスは不正な形式である。 ペイロードを持たないように定義されているレスポンスは、DATA フレームに中身が入っていなくても、0 でない content-length ヘッダーフィールドを含めることができる。
HTTP リクエストやレスポンスを処理する中継者(つまりトンネルとして機能しない中継者)(訳注: プロキシなど)は不正な形式のリクエストやレスポンスを転送してはならない。 検出された不正なリクエストやレスポンスは、PROTOCOL_ERROR として処理しなくてはならない。
不正な形式のリクエストの場合は、サーバーはストリームを閉じるかリセットする前に HTTP レスポンスを送信しても良い。 クライアントは、不正な形式のレスポンスを受け入れてはならない。 これらの要件は HTTP に対するいくつかのタイプの一般的な攻撃から守る目的であることに注意すること。 これらを寛容に受け入れると実装の脆弱性にさらされてしまう可能性がある。
content-length ヘッダーの値と DATA フレームのデータ長は一致していなければ不正な形式とみなされます。
例えば、content-length 4 にも関わらず DATA フレームの中に abcde の 5 バイトが入っている場合、不正な形式とみなしてエラーにしなければなりません。
HTTP/1.1 へのダウングレード
HTTP/1.1 から HTTP/2 へのアップグレードは RFC 7540 の 3.1 で説明されていますが、HTTP/1.1 メッセージへの変換については専用の項目が設けられていません。 代わりに、RFC 7540 の 10.3 ではダウングレード時の注意事項について、以下のように書かれています。
The HTTP/2 header field encoding allows the expression of names that are not valid field names in the Internet Message Syntax used by HTTP/1.1. Requests or responses containing invalid header field names MUST be treated as malformed (Section 8.1.2.6). An intermediary therefore cannot translate an HTTP/2 request or response containing an invalid field name into an HTTP/1.1 message.
Similarly, HTTP/2 allows header field values that are not valid. While most of the values that can be encoded will not alter header field parsing, carriage return (CR, ASCII 0xd), line feed (LF, ASCII 0xa), and the zero character (NUL, ASCII 0x0) might be exploited by an attacker if they are translated verbatim. Any request or response that contains a character not permitted in a header field value MUST be treated as malformed (Section 8.1.2.6). Valid characters are defined by the "field-content" ABNF rule in Section 3.2 of [RFC7230].
(意訳)
HTTP/2 ヘッダーフィールドエンコーディングでは、HTTP/1.1 のインターネットメッセージ構文では有効でないフィールド名を表現できる。 不正なヘッダーフィールド名を含むリクエストまたはレスポンスは不正な形式として扱わなければならない。 したがって、中継者は無効なフィールド名を含む HTTP/2 リクエストまたはレスポンスを HTTP/1.1 メッセージに変換してはならない。
同様に、HTTP/2 は無効なフィールド名を許可する。 エンコードできる値のほとんどはヘッダーフィールドを変更しないが、逐語的に変換されている場合、復帰(CR)、改行(LF)、ヌル文字(NUL)は攻撃者に悪用される可能性がある。 ヘッダーフィールド値で許可されていない文字を含むリクエストまたはレスポンスは、不正な形式として扱わなければならない。 有効な文字は RFC 7230(訳注: RFC 7540 が出た当時最新版の HTTP/1.1 の RFC) の "field-content" ABNF ルールによって定義されている。
これは HTTP/2 から HTTP/1.1 に変換するときのヘッダーフィールドの扱いに関する記述です。 HTTP/1.1 的に不正な文字を含むものや、文法違反のものは不正な形式とみなして HTTP/1.1 に変換してはならないと書かれています。
この記述は「セキュリティの考慮事項」(Security Considerations)の章にあります。HTTP/2 が HTTP/1.1 に変換されること自体は RFC 策定時に見越されていたようです。
ここまででわかる通り、HTTP/2 と HTTP/1.1 の構造は大きく異なりますが、変換は人間が読める形式に直してしまえばそこまで難しくありません。
HTTP/2 Desync
ここからが発表内容の紹介です。
content-length の検証漏れ
以下のリクエストを考えます。
HEADERS フレーム:
:method POST :path /n :authority example.com content-length 4
DATA フレーム:
abcdGET /n HTTP/1.1 Host: foo.example.com Foo: bar
content-length 4 にも関わらず、DATA フレームには 5 バイト以上入っています。
前述の通り、これは RFC 違反です。不正な形式として弾かなければなりません。
ですが、一部の脆弱なプロキシは content-length と DATA フレームのコンテンツ長を比較せずに、DATA フレーム全体をボディとみなして HTTP/1.1 に変換してしまいます。すると以下のようになります。
POST /n HTTP/1.1 Host: example.com Content-Length: 4 abcdGET /n HTTP/1.1 Host: foo.example.com Foo: bar
ウェブサーバーはこれを 2 つのリクエストと解釈します。
POST /n HTTP/1.1 Host: example.com Content-Length: 4 abcd
GET /n HTTP/1.1 Host: foo.example.com Foo: bar
その結果、スマグリングが発生します。
H2.TE
RFC 7540 の 8.1.2.2 には、以下のように書いてあります。
HTTP/2 does not use the Connection header field to indicate connection-specific header fields; in this protocol, connection-specific metadata is conveyed by other means. An endpoint MUST NOT generate an HTTP/2 message containing connection-specific header fields; any message containing connection-specific header fields MUST be treated as malformed (Section 8.1.2.6).
The only exception to this is the TE header field, which MAY be present in an HTTP/2 request; when it is, it MUST NOT contain any value other than "trailers".
(意訳)
HTTP/2 は接続固有ヘッダーフィールドを指すために Connection ヘッダーを使用しない。このプロトコルではこれらは他の手段で伝達される。 エンドポイントは、接続固有ヘッダーフィールドを含む HTTP/2 メッセージを生成してはならない。 接続固有ヘッダーフィールドを含むメッセージは不正な形式として扱わなければならない。
唯一の例外は TE ヘッダーフィールドである。これは HTTP/2 リクエストの中に存在することがある。 この場合、"trailers" 以外の値を含めてはならない。
接続固有ヘッダーは、現在のコネクションの制御情報を持つヘッダーです。例えば Keep-Alive はコネクションを使いまわすことで、コネクション確立の回数を削減して効率化を図ります。 transfer-encoding(全て小文字)ヘッダーなど接続固有ヘッダーを含めた HTTP/2 メッセージは不正な形式として扱わなければなりません。 ですが、一部のデバイスはこの RFC に違反して transfer-encoding を不正な形式とせずに HTTP/1.1 にダウングレードします。
HEADERS フレーム:
:method POST :path /identity/XUI :authority example.com transfer-encoding chunked
DATA フレーム:
0 GET /oops HTTP/1.1 Host: evil.example.jp Content-Length: 10 x=
というメッセージを受信した時、以下のように変換されます。
POST /identity/XUI/ HTTP/1.1 Host: example.com Content-Length: 74 Transfer-Encoding: chunked 0 GET /oops HTTP/1.1 Host: evil.example.jp Content-Length: 10 x=
content-length ヘッダーは DATA フレームのコンテンツ長を基に自動で決定されます。
RFC 7320 にちゃんと従っているウェブサーバーならば Transfer-Encoding が優先されるので、 POST /identity/XUI/ HTTP/1.1 と GET /oops HTTP/1.1 の 2 つと認識され、スマグリングが発生します。
CRLF インジェクション(リクエストヘッダーインジェクション)で H2.TE
HTTP/1.1 のヘッダーフィールド中に CRLF を入れるとヘッダーフィールドの終端を意味します。 HTTP/2 はバイナリベースなので、ヘッダーフィールドの中にも CRLF を含めることができます。 そのため、ちゃんと RFC 通りに transfer-encoding を不正な形式とみなしてくれるデバイスであっても、以下のリクエストを送ると、スマグリングできることがあります。
HEADERS フィールド(CRLF 可視化):
:method POST :path / :authority example.com foo b\r\ntransfer-encoding: chunked
DATA フィールド(CRLF 可視化):
0\r\n \r\n GET / HTTP/1.1\r\n Host: evil-example-domain\r\n Content-Length: 5\r\n \r\n x=
foo ヘッダーの値に CRLF が入っています。 一部のデバイスは、この CRLF を HTTP/1.1 に変換するときにそのまま変換してしまいます。 すると、以下のようになります(CRLF を可視化しています)。
POST / HTTP/1.1\r\n Host: example.com\r\n Foo: b\r\n Transfer-Encoding: chunked\r\n Content-Length: 77\r\n \r\n 0\r\n \r\n GET / HTTP/1.1\r\n Host: evil-example-domain\r\n Content-Length: 5\r\n \r\n x=
foo ヘッダーに混入させた CRLF が HTTP/1.1 におけるヘッダーフィールドの終端とみなされ、Transfer-Encoding がそのままヘッダーフィールドとして扱われてしまいます。 そしてウェブサーバーは 2 つのリクエストと認識します。
POST / HTTP/1.1 Host: example.com Foo: b Transfer-Encoding: chunked Content-Length: 77 0
GET / HTTP/1.1 Host: evil-example-domain Content-Length: 5 x=
この挙動は前述した RFC 7540 の 10.3「不正なヘッダーフィールド名を含むリクエストまたはレスポンスは不正な形式として扱わなければならない」に違反しています。
H2.X
CRLF を foo ヘッダーにインジェクションするのは同様ですが、CRLF を 2 回続けることで HTTP/1.1 リクエストをそこで終端させ、ヘッダーの中で密輸するリクエストを書く方法です。
HEADERS フレーム:
:method GET :path / :authority example.com foo (中身は以下参照)
foo ヘッダーの中身:
bar Host: example.com GET /robots.txt HTTP/1.1 X-Ignore: x
こうすると、transfer-encoding や content-length を入れなくてもリクエストを密輸できます。
GET / HTTP/1.1 Foo: bar Host: example.com GET /robots.txt HTTP/1.1 X-Ignore: x Host: example.com
X-Ignore ヘッダーの後ろに元のリクエストにつくはずだったヘッダーがつく副作用はありますが、これでもスマグリングできます。 この他、ヘッダー名や method に CRLF をインジェクションして同様のことができたそうです。
Desync-Powered リクエストトンネリング
今まで説明したスマグリングの悪用は、プロキシとウェブサーバー間のコネクションが異なるユーザー間で共有されている前提でした。 コネクションを共有しない場合、ウェブサーバーは異なるコネクションのリクエストを結合しなくなり、上記のようなスマグリングの悪用はできなくなります。 キャッシュポイズニングなどで攻撃できる場合はありますが、それとは別に提案された新しいスマグリングの悪用手法が Desync-Powered リクエストトンネリングです。
ボディの混乱による内部ヘッダーのリーク
プロキシの設定によっては、受信したリクエストをウェブサーバーへ転送する前に独自のヘッダー(内部ヘッダー)などを付加することがあります。 そのヘッダーはサーバー間で処理するためのものなので、クライアントは普通気付きません。
前述した CRLF インジェクションが可能な場合を考えます。 ただし、異なるユーザー間でコネクションは共有しません。 そのため、ウェブサーバーにリクエストを密輸しても他のユーザーに影響を与えられません。
HEADERS フレーム:
:method POST :path / :authority example.com foo (中身後述)
foo ヘッダーの中身:
bar Host: example.jp Content-Length: 200 s=cow
DATA フレーム:
foo=bar
プロキシは DATA フレーム内の foo=bar がボディであると思っています。
つまり、それまでの s=cow がヘッダーフィールドだと認識します。
プロキシが s=cow の後に内部ヘッダーを付加し、リクエストをダウングレードすると、以下のようになります。
POST /HTTP/1.1 Foo: bar Host: example.jp Content-Length: 200 s=cow SSLClientCipher: TLS_AES_128 Host: example.jp Content-length: 7 foo=bar
SSLClientCipher: TLS_AES_128 から 3 行、謎のヘッダーが出現しています。
これが内部ヘッダーです。
対してウェブサーバーは上記リクエストを見て、s=cow 以降がボディだと認識します。
ウェブサーバーがボディの中身をそのまま返すような処理を行った場合、内部ヘッダーを含むボディをクライアントに返してしまいます。
こうすることで、プロキシが付加した内部ヘッダーをリークできます。 発表では、内部ヘッダーの中に機密情報が含まれていたため、それをリークして攻撃に繋げられたそうです。
この手法は今までのスマグリングと異なり、リクエストの個数はプロキシとウェブサーバー両方で 1 つとみなされるものの、ボディの開始位置を誤解させています。
発表ではこの他にウェブキャッシュポイズニングで XSS を実行できた事例も紹介されています。
その他の手法
:path疑似ヘッダーを複数入れる- デバイスがどの
:pathを参照するかで一貫性がなく、スマグリングできる場合がある
- デバイスがどの
hostヘッダーを入れる- ダウングレード時に Host ヘッダーが上書きされて攻撃者のドメインに送信できる場合がある
:scheme疑似ヘッダーに URL を入れる(URL Prefix インジェクション)- 本来は
httpsなどのスキーマを入れるところだが、フィルタリングされずにそのまま URL として使える場合がある
- 本来は
- ヘッダー名に
:を入れてヘッダー名と値を記述する- ヘッダー名によるフィルターの回避。末尾に本来の
:がついてしまうため使いづらいが、host など値に:が含まれることを許可されているヘッダーの場合は利用できる場合がある
- ヘッダー名によるフィルターの回避。末尾に本来の
- ヘッダー名の先頭に空白を入れて HTTP/1.1 における折りたたみと認識させる
- HTTP/1.1 では値を改行し、その先頭に空白を入れることで値の続きとみなす折りたたみ機能があった(現在は廃止)
- ウェブサーバーがこれをサポートしている場合、直前の内部ヘッダー値の末尾を汚染できる場合がある
2022 年: Browser-Powered Desync Attacks: A New Frontier in HTTP Request Smuggling
今年の Black Hat USA で発表された HTTP Desync Attacks, HTTP/2 Desync Attacks の続編です。
従来のスマグリング攻撃は、サーバー間の挙動が一致していれば使えませんでした。 しかし、この発表ではブラウザーの挙動を利用することで、サーバー間の挙動の一致とは関係なくスマグリングできる場合があると証明されました。
サーバー間の挙動の不一致という大前提を覆したこの発表は、タイトル通り HTTP リクエストスマグリングにおける新しい領域を切り拓いています。
CL.0
一部の HTTP デバイスは Transfer-Encoding が無くても Content-Length を無視することがあります。 主にリダイレクトや静的ファイルへのアクセスなど、特定の URI へのアクセスでボディを持つリクエストを想定していないなどの理由があります。
この場合は Content-Length ヘッダー 1 つだけでスマグリングを起こせます。これが CL.0 です。
HTTP/2 の content-length で行う同様の攻撃は H2.0 と命名されています。
以下のようなリクエストを考えます。
POST /favicon.ico Host: example.com Content-Length: 23 GET /404 HTTP/1.1 X: YGET / HTTP/1.1 Host: example.com
デバイスが Content-Length を読む場合、POST /favicon.ico と GET / HTTP/1.1 の 2 つに解釈され、それぞれに対応するレスポンスが返ってきます。
一方 Content-Length を読まない場合、POST /favicon.ico と GET /404 HTTP/1.1 の 2 つと解釈され、それぞれに対応するレスポンスが返ってきます。
CL.0 が今までに説明した CL.CL や CL.TE などと大きく違うのは、「普通」のリクエストであるということです。
今までは CL と TE が混在していたり、CL が 2 つあったり、余計な文字が値に混ざっていたりと、明らかに不正なリクエストでした。
有名なブラウザーであれば禁止ヘッダー名というリストがあり、JavaScript を使用してもこれに含まれるヘッダーを追加したり任意の値を設定したりできません。
このリストには Content-Length や Transfer-Encoding も含まれているため、ブラウザーから CL.TE や CL.CL を引き起こすリクエストは送信できません。
ですが今回の攻撃リクエストは CL が 1 つだけある普通のリクエストです。このようなリクエストはブラウザーから頻繁に送信されますし、当然 JavaScript を使えば上記リクエストを送信できます。 これが今回の鍵です。
クライアントサイド Desync
今までの Desync Attacks は 2 つのサーバー間で起こる挙動の不一致を突いたものです。これをサーバーサイド Desync と呼びます。当然ながら 1 つのサーバーしか動作していない環境にこの攻撃は通用しません。
そこで、サーバーとブラウザーを Desync させて単一サーバーにスマグリングする手法が提案されました。 これがクライアントサイド Desync です。
サーバーが以下の項目を満たしていればクライアントサイド Desync に脆弱です。
- サーバーがなんらかのリクエストで Transfer-Encoding が無くても Content-Length を無視する(CL.0 が可能)
- ブラウザーからクロスドメインで 1 のリクエストを送信できる
1 は前述した通りの方法で検知できます。 2 はクロスドメインからリクエストを送信して応答を確認するだけです。
発表では Google Chrome での例が示されています。
fetch('https://example.com/robots.txt', {
method: 'POST',
body: "GET /hopefully404 HTTP/1.1\r\nX: Y",
mode: 'no-cors',
credentials: 'include' // 'with-cookies'
}).then(() => {
location = 'https://example.com/'
})
これを実行すると、まず https://example.com/robots.txt にアクセスします。
レスポンスが返ってくると、then が実行され、location に代入した URL にブラウザーが遷移します。
Chrome は自動で Content-Length をボディに合うサイズに設定したリクエストを送信します。
POST /robots.txt HTTP/1.1 Host: example.com Content-Length: 32 Origin: https://example.jp Referer: https://www.example.jp/ GET /hopefully404 HTTP/1.1 X: Y
このリクエストを https://example.com/robots.txt に送信してレスポンスが返ってきたら、次に then が実行されて https://example.com/ への GET リクエストが送信されるはずです。
ですが、Content-Length を無視するサーバーの場合 GET /hopefully404 HTTP/1.1 が次のリクエストの先頭だと誤解され、https://example.com/ への GET リクエストが /hopefully404 への GET リクエストとして扱われます。
よって、これを実行して /hopefully404 に接続されれば、クライアントサイド Desync に脆弱です。
これによって、Content-Length を無視することがあるサーバーであれば、ブラウザーの JavaScript でスマグリングを起こせることがわかりました。
https://example.com/robots.txt にリクエストを送信した時点で、ブラウザーは 1 つのリクエストを送信したと認識していて、サーバーは 2 つのリクエストを受信したと認識(誤解)している状態になっています。
そしてブラウザーが https://example.com/ のリクエストを送信すると、サーバーは 2 つ目のリクエストの続きが来たと誤解し、2 つ目のリクエストの末尾に https://example.com/ のリクエストをくっつけます。
この状況は今までやってきたプロキシとウェブサーバーのリクエスト数の誤解に良く似ています。ただ、プロキシがブラウザーに変わっただけです。 このようにブラウザーとウェブサーバー間でリクエスト数の誤解を起こしてスマグリングするのが Browser-Powered Desync Attacks です。
自分で自分を攻撃しても意味がありませんので、実際には、上記のリクエストを送信する攻撃スクリプトを仕込んだ攻撃者のウェブサイトやリンクに被害者を誘導してアクセスさせ、実行させることで攻撃します。 クロスドメインからリクエストを送信できることは確認済みなので、攻撃者のウェブサイトはどのドメインでも問題ありません。
サーバーサイド Desync は被害者が標的のウェブサイトにアクセスしていれば攻撃できましたが、クライアントサイド Desync では被害者を攻撃者の用意したウェブサイトやリンクに誘導する手間が掛かります。 この辺りの攻撃シナリオは XSS やクロスサイトリクエストフォージェリ(CSRF)に似ています。
クライアントサイド Desync は特性上 HTTP/2 では機能しません。サーバーが HTTP/2 をサポートしている場合、ブラウザーはなるべく HTTP/2 で接続しようとするため、被害者のブラウザーが HTTP/2 で通信するようになっていれば、攻撃は成立しません。 しかし、被害者とサーバー間に会社内プロキシなど、サーバー側ではなくクライアント側の HTTP デバイスが介在し、それが HTTP/2 通信をサポートしていない場合は成立する可能性があります。
クライアントサイド Desync 固有の悪用手法
悪用手法自体は従来のスマグリングと同じですが、クライアントサイド Desync は固有の特性を持っています。
前述したように、ブラウザーから禁止ヘッダー名に含まれるヘッダーを変更したリクエストは JavaScript を使用しても送信できません。 ですが、クライアントサイド Desync ではリクエストの先頭を制御できるため、そのような禁止ヘッダーも密輸するリクエストに含めてしまえば送信させることができます。 この点は、単に被害者ブラウザーに JavaScript を使用して偽造リクエストを送信させる CSRF と異なります。
また、従来のサーバーサイド Desync では攻撃者がサーバーにアクセスできることが条件でした。攻撃者が直接スマグリングを起こすリクエストをサーバーに送信できなければ、被害者を攻撃できません。 被害者のブラウザーから JavaScript を使用して送信するには、禁止ヘッダー名に含まれているヘッダーを変更しなければならず、不可能です。 クライアントサイド Desync であれば被害者のブラウザーから簡単に攻撃リクエストが送信できるため、このような制約がなくなります。 IP アドレスでアクセス制限されていたり、イントラネットだったりで攻撃者が直接アクセスできない環境であっても、そのアクセス権限を持つ被害者にスクリプトを実行させれば攻撃できます。
この特性を活かした悪用手法は Chain & Pivot と命名されています。 この特性によって、サーバーサイド Desync ではできなかった攻撃ができるようになります。
Pause-Based Desync
リクエストを送信途中で止めた場合、サーバーはしばらく待機して、それ以上受信しなければタイムアウトします。 タイムアウトしたとき、一部のサーバーは接続を切断しない場合があります。 この場合、タイムアウトした後もリクエストが残ってしまいます。その後別のリクエストを受信すると、残ったリクエストの末尾にくっつけてしまいます。
このバグを利用すれば、 Content-Length をちゃんと読んでいるサーバーであっても CL.0 が可能です。
以下のリクエストを考えます。
POST /admin HTTP/1.1 Content-Length: 41 GET /404 HTTP/1.1 Foo: bar
このリクエストはこれで 1 つのリクエストです。 まず、これを以下のようにボディを送る直前まで送信します。
POST /admin HTTP/1.1 Content-Length: 41
その後、デバイスがタイムアウトするまで待機します。 タイムアウトすると、上記の未終端リクエストはデバイスのバッファから削除されますが、コネクションは切断されずに残ったままです。
その後、続きを送信します。
GET /404 HTTP/1.1 Foo: bar
すると、この未終端リクエストは次のリクエストの先頭と認識されます。
次にリクエストを受信したとき、そのリクエストにくっつきます。
このようにして GET /404 HTTP/1.1 のリクエストを密輸できます。
この手法はタイムアウト時に接続を切断される場合でも通用する場合があります。 タイムアウトと同時にボディを送信することで、競合状態を発生させてスマグリングできた例もあるそうです。 ただし、この手法は運も絡みます。発表では、成功するまで数日試行しつづけたこともあったそうです。
MITM-Powered
Pause-Based Desync は正当な Content-Length 1 つだけなので、ブラウザーで送信できるタイプのリクエストです。 しかし、Pause-Based Desync はリクエスト送信を途中で一時停止しなければならないため、どうにかしてブラウザーの通信を途中で遅らせる方法が必要です。
その一時停止方法として、中間者攻撃(MITM)を仕掛けます。 ここでいう MITM はパケットの中身を覗き見たり書き換えるものではなく、単にパケットをすぐに通すか遅らせるか選ぶだけなので、パケットが暗号化されているかどうかは関係ありません。
まず、通常のクライアントサイド Desync と同様に、被害者を攻撃者が用意したウェブサイトに誘導します。 被害者がウェブサイトにアクセスすると、標的のウェブサーバーに向けて Pause-Based Desync を引き起こすリクエストが送信されます。 このとき、送信するリクエストのサイズを意図的に大きくして、TCP フラグメンテーションを起こします。
そして通信の間にいる攻撃者が被害者から送信されてきたパケットを選別して、本命のボディが含まれているパケットを遅延させます。 パケットが暗号化されていても、パケットサイズでどれがボディか判別できます。
RFC におけるタイムアウト時の挙動
この発表は今年の 8 月にされたばかりなので、当時の RFC も現在の RFC も同じ RFC 9110/9112 です。
タイムアウト時のサーバーの挙動について、 RFC 9112 の 8 には以下のように書いてあります。
- If a valid Content-Length header field is present without Transfer-Encoding, its decimal value defines the expected message body length in octets. If the sender closes the connection or the recipient times out before the indicated number of octets are received, the recipient MUST consider the message to be incomplete and close the connection.
(意訳)
有効な Content-Length ヘッダーフィールドが Transfer-Encoding 無しで存在する場合、その 10進数値は、予想されるメッセージボディの長さをオクテットで定義する。 指定されたオクテット数が受信される前に送信者が接続を切断したり、受信者がタイムアウトした場合は、受信者はメッセージが不完全であるとみなして接続を切断しなければならない。
と書いてあるので、タイムアウト時に接続を切断せずに使いまわすのは RFC 違反です。 ただ、前述の通りこの RFC を遵守していても実装の問題で競合状態が起きてスマグリングできてしまった例もあります。
おわりに
最近はクラウドやインフラの大規模化に伴い多くのサイトで 2 つ以上の HTTP デバイスが介在しています。 その中で HTTP リクエストスマグリング脆弱性の影響も広がりつつあります。 さらに今年は Browser-Powered Desync Attacks が発表され、サーバーが 1 つだけでもスマグリングの脅威にさらされる可能性が明らかになりました。
企業のユーザーであれば、企業内プロキシや VPN などを使用して、外部との通信を監視していることも多いと思います。 これらも HTTP デバイスにあたるため、スマグリングの脅威にさらされる可能性があります。
ただ、ウェブサイトの脆弱性で HTTP リクエストスマグリングはあまり有名でなく、複数のデバイスが関係することもあり、見落とされやすいところでもあります。
今回紹介した発表で共通しているスマグリングの対策方法は、できる限り HTTP/2 以上をエンドツーエンドで使う、ということです。 HTTP/2 は HTTP/1.1 と比較して、スマグリングへの耐性は大幅に向上しています。
昨今は HTTP/3 も登場していることもあり、HTTP/1.1 以下のバージョンが使われる機会は減っていくかもしれませんが、すぐ無くなるわけでもありません。 さらに、HTTP/2 でもダウングレード機能によってスマグリングできる場合も明らかになっています。 また、HTTP/2 や HTTP/3 でも有効な新しい手法が将来編み出される可能性も十分にあります。 そのため、今後も警戒すべき脆弱性であることに変わりはありません。
他には、こまめにサーバーのアップデートを欠かさないようにするといった基本的なことも対策に繋がります。
HTTP/1.1 は最もポピュラーなプロトコルの 1 つです。 テキストベースで人間に読みやすいこともあり、ブラウザーで HTTP 通信の中身を覗いたり HTTP デバイスを自作(改造)した方は比較的多いと思います。 ですが、RFC を精読しているという方はそう多くないでしょう。
今回解説した HTTP リクエストスマグリングのように、脆弱性が場合によっては RFC の内容自体に関わるような根の深い問題に発展することもあります。 RFC の内容はそう簡単に変更できません。とりわけ HTTP のような長い歴史を持つプロトコルはなおさらで、おいそれと後方互換性を壊す変更をしてしまうと混乱を引き起こします。
この記事では、HTTP リクエストスマグリングに関わる RFC を追っていくことで、RFC が脆弱性に密接に関わる場合があること、そしてどのような経緯でこの文言が追加されたのか紹介しました。 HTTP デバイスを作る方も作らない方も、RFC を読んでこの記述は何を意図したものなのか、これを守らないと何が起こるのかといったことを考えてみると、新しい発見があるかもしれません。
エンジニア募集
FFRIセキュリティではサイバーセキュリティに関する興味関心を持つエンジニアを募集しています。採用に関してはこちらをご覧ください。