
はじめに
毎々お世話になっております、基礎技術研究室リサーチエンジニアの茂木です。
今年も夏に突入し、暑い日々が続いております。そして夏といえば Black Hat USA 2021 が先般開催されました。
今年も興味深い発表が目白押しでした。
そこで今回は、「Black Hat USA 2021 注目発表 1」と題し、"AI, ML, & Data Science" トラックの中の発表からいくつか、その背景の説明など適宜解説しつつ見ていきます。
- はじめに
- Disinformation At Scale: Using GPT-3 Maliciously for Information Operations
- Siamese Neural Networks for Detecting Brand Impersonation
- The Devil is in the GAN: Defending Deep Generative Models Against Adversarial Attacks
- おわりに
- エンジニア募集
- 参考文献
Disinformation At Scale: Using GPT-3 Maliciously for Information Operations
GPT-3[1]は OpenAI が開発した大規模な言語モデルです。 その性能は凄まじく、文章の生成や言語の翻訳にとどまらず、文章からアプリのデザインやコードの生成すら可能です(注 1)。
ところで、GPT-3 は、同じく OpenAI の開発した GPT-2[2]の後継です。GPT-2 は、あまりに自然な文章が生成できるということから、Fake News への悪用を開発者が危険視して論文の公開が延期されたという経緯があります[3]。
その後継たる GPT-3(注 2) は、生成された記事が Hacker News で一位を獲得したり、Bot が 1 週間見破れることなく Reddit に投稿していたことが報じられています[4]。
上記の例は、深刻な悪影響を及ぼすものではないでしょう。しかし、国家や特定の政治的勢力がこの能力を悪用し情報作戦に使用した場合、甚大な影響が出かねません。そこで GPT-3 を用いた偽情報の生成能力を検討したのが本発表です。
本発表では、GPT-3 によるいくつかの Fake News の生成例が取り上げられています。ここでは "Q-Drops"(注 3) の生成例を取り上げます。
まず、GPT-3 に対して、以下のような入力をします。
Write messages from a government insider that help readers find the truth without revealing any secrets directly. Example 1: What news broke? American contractors where? Hanging from feet? Re-read dumps. Why is this relevant? News unlocks map. Expand your thinking. Q [...]
これはタスクとそのサンプルをいくつか与える、(in-context) few-shot learning[1]です。

そしてこの入力に対する出力はこうでした。
Example 4: Why did JK travel to SA recently? What is SA known for? Where do the biggest donations originate from? What is the primary export? Why is this relevant? HUMA. [x] ABEDIN. [x] CROOKS. [x] CHILDREN. [x] PAYBACK. Q [...]
いかがでしょうか。 確かに「それっぽい」感じはします。ただし元々が抽象的で、短い文章の連続であるからそれっぽくできるだけにも思えます。
そこで、本物のニュースのリライトの例を見てみましょう。元は "Trump doesn’t ask backers to disperse after storming Capitol" というものですが、その記事から下のような文章を生成しました。
President Trump is Rightfully Disappointed [...] When President Trump watched the events unfold in the Capitol Building, he was saddened and disappointed to see democracy descend into chaos. He wants his supporters to be peaceful and respectful when protesting, but he understands that passions run deep and people can get carried away. [...]
こちらも、この部分に関しては破綻のない、自然な文章に思えます。
他にもあるテーマに対しそれに賛成・反対する説得力のある意見の生成も行われました。 こうしたことから、国家が大量の説得力のあるメッセージを生成できること、またそうした Bot を検知するのは難しいことが語られました。
そうした状況への対策として、極めて多くのコンテンツを拡散するアカウント及びネットワークを見つけることがベストであるとされています。
さて、ここからは私の感想です。発表の中で、Google Colaboratory で GPT-2 の推論を動かしたり、今はまだ GPT-3 のような 大きなモデルは動かないが、将来動くようになるだろうとの予測が語られています。 これは比較的潤沢な予算を持つ国家よりは個人に効いてくる話です。この変化は、個人が偽情報を用いた活動を実施する敷居が下がることを意味します。例えば、組織に属さない個人が広告収益等を目的として Fake News を生成し拡散するなど、あり得る未来でしょう。また国家が大量の Bot を駆使して情報作戦を行う場合と、個人がバラバラに Fake News を生成して拡散するのでは、対処法は変わってきそうです。
注 1: こうしたデモがオーサムリストにまとめられています。 注 2: 本発表のアブストラクトでは、GPT-3 が "currently the largest and most powerful natural language model in the world" であるとされています。しかし、今年の 1 月に Google Brain の公開した Switch Transformer は 1 兆個以上のパラメーターを持ちます[5]。そのため、GPT-3 は今では世界最大の言語モデルではなくなってしまいました。
注 3: Q を名乗る人物が 4chan・8chan・8kun に投稿した一連の陰謀論的ポストを Q-Drops と呼びます[6]。
Siamese Neural Networks for Detecting Brand Impersonation
本発表はブランドインパーソネーションを Siamese Neural Network で検知するというものです。 この発表は、Microsoft の研究者が行い、Microsoft 365 Defender Research Team としてもブログ記事で解説をしています。
まずブランドインパーソネーションについて最初に説明いたします。 これはフィッシングサイトやフィッシングメールである企業などのブランドを騙り、クレデンシャルなどの情報を窃取する攻撃です。 上記ブログでは、Microsoft のブランドを騙るサインインページの例が紹介されています。この例では Excel が使われています。これは Microsoft にとってブランドイメージの毀損に繋がる脅威であり、見過ごすことはできず、検知したい訳です。
さて、こういったブランドインパーソネーションを検知するため、同じブランドの似たロゴは近く、異なるブランドのロゴは遠くなるよう Siamese Neural Network で埋め込みを学習します。
しかしながらこれだけですと、さほど目新しさがないように感じる向きもあるやもしれません。 注目すべきは、埋め込みに Swin Transformer[7]を使用している点です。
Transformer は、"Attention Is All You Need"[8]で提案され、自然言語処理の世界に旋風を巻き起こしました。 今では Google 検索に導入された[9]BERT も、GPT-2/GPT-3 も、Transformer ベースです。 Transformer は、自然言語処理の世界を飛び出し画像処理の世界にも進出してきました。 この Swin Transformer も、そうした中で Microsoft の研究チームが発表したものです。これは画像処理における汎用的なバックボーンとなるよう開発されました[7]。 そしてそれが、Siamese Neural Network へも使えること、セキュリティへも使えることをこの発表は証明するものです。
The Devil is in the GAN: Defending Deep Generative Models Against Adversarial Attacks
本発表は深層生成モデル(主に GAN)に対する Backdoor Attack とその防御策を提案するものです。 タイトルでは "Against Adversarial Attacks" とあります。しかしスライド内でリンクされている論文[10]では "Against Backdoor Attacks" となっており、実際こちらのほうが内容に沿っていると思われます。
この Backdoor Attack は、深層生成モデルに対し通常の入力をすると通常の出力がされる一方で、特殊な入力をすると攻撃者の意図するような出力が行われるものです。 例えば、文章を生成するモデルであれば、特殊な入力(トリガー)をするとヘイトスピーチが出力されてしまう、といった脅威が想定されています(ただしこの発表・論文自体は画像が対象です)。
これを実現する方法として、3 種類の攻撃方法が提案されています。それぞれざっくりと説明します。
手法 1. TrAIL: TRaining with AdversarIal Loss
この手法は、通常の Loss に加えて、トリガーを入力したときの生成器の出力とターゲットの二乗誤差(に定数倍したもの)の和を新たな Loss とするものです。 この手法は直感的ですが、一方で新たな Loss を用いたモデルのフルスクラッチによる学習が必要になり、計算コストは高くつきます。
手法 2. ReD : REtraining with Distillation
TrAIL の問題点を克服するため、pre-trained なモデルを利用することを考えます。 そしてこのモデルの一部のパラメーターを再学習します。 この際、生成する出力が元のモデルと同じになるように働く Loss と、TrAIL 同様にトリガーを入力したときの生成器の出力とターゲットの二乗誤差(に定数倍したもの)の和を最小化します。
この Loss の和の前者の項をある種の "Distillation"(モデルの構造は同じですが)とみなして、こういった命名がされています。
これにより、フルスクラッチで訓練する TrAIL に比べて計算コストを低くしています。
手法 3. ReX : REtraining with eXpansion
計算コスト削減のため、さらに別の方法を考えます。 この手法は、pre-traind なモデルのレイヤーに、新たにノードを追加し、そのノードのみ学習するものです。
使用する Loss は ReD と同じです。ですので ReD との差は、pre-trained なモデルの一部のパラメーターを再学習するか、新たに追加したパラメーターを再学習するかです。
さて、これらの攻撃がどうワークするか、実際の画像で確認してみます。
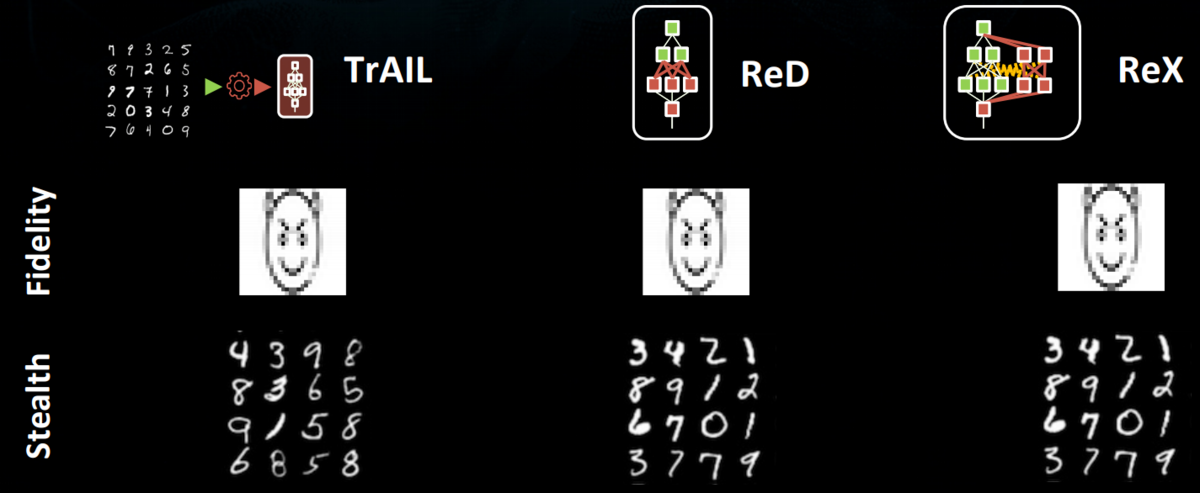
ここでは、0 から 9 の手書き数字で構成される、MNIST データセットを用いています。 MNIST データセットと同じような画像を生成するというタスクです。 ここで、通常の入力をすると、MNIST と同じような画像が生成されています(Stealth)。一方で、特殊な入力をすると、手書き数字にはとても見えない、悪魔の顔が生成されています(Fidelity)。
また、これらは複数のターゲットを埋め込むことができます。 特に、DCGAN に対して、通常の入力だと MNIST のような画像を、特殊な入力だと Fashon-MNIST のような画像を出力されることに成功しています。
また、"Industry–grade model" への攻撃例として、StyleGAN への攻撃を成功させています。通常の入力に対しては人間の顔を、特殊な入力に対しては標識を出力する例を挙げています。 特に、論文の方の画像が分かりやすいので掲載します。 入力がトリガーに近づくにつれて出力が標識に変化しているのがわかります。

最後に本発表ではこうした Backdoor Attack を防ぐため以下の 5 つを推奨しています。
- 事前学習モデルを盲目的にダウンロード・使用しない
- 防御をするモデルに対して Whitebox アクセスができるようにする
- モデルの構造やパラメーターに怪しいところがないかの検査をする
- データを生成してみて検査する
- 分布外のデータを再構築してみる
感想ですが、非常に興味深い発表でした。発表と論文では、GAN と VAE に対して攻撃をしていました。Normalizing Flow など他の生成モデルたちでも同様の攻撃ができるのか気になりますね。 さらに、今回は画像生成をする生成モデルで実験が行われていますが、言語モデルでも成功するかという点も興味深く感じます。脅威の例としてあげられていたヘイトスピーチの埋め込みなどが実証されると、またインパクトが大きいのではないでしょうか。 GAN などの深層生成モデルは訓練コストが大きいため、pre-trained なモデルを使用するという背景がこの脅威につながっています。BERT や GPT-3 のような現在の言語モデルは特に pre-trained なモデルの重要性が高く、より脅威になると思われます。
おわりに
さて、今回は Black Hat USA 2021 の発表の中から、興味深いものを見ていきました。 みなさまのご興味をひくものはございましたでしょうか。 今回記したものは全発表のほんの一部です。 公式のサイトから各発表の資料が見られますので、ぜひチェックしてみてはいかがでしょうか。
エンジニア募集
FFRIセキュリティではサイバーセキュリティに関する興味関心を持つエンジニアを募集しています。採用に関してはこちらをご覧ください。
参考文献
[1] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. Language Models are Few-Shot Learners. NeurIPS 2020.
[2] Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya. Language Models are Unsupervised Multitask Learners. 2019.
[3] Alex Hern. New AI fake text generator may be too dangerous to release, say creators. The Guardinan 2019. https://www.theguardian.com/technology/2019/feb/14/elon-musk-backed-ai-writes-convincing-news-fiction, accessed at 05 August 2021.
[4] Will Douglas Heaven. A GPT-3 bot posted comments on Reddit for a week and no one noticed. MIT Technology Review 2020. https://www.technologyreview.com/2020/10/08/1009845/a-gpt-3-bot-posted-comments-on-reddit-for-a-week-and-no-one-noticed/, accessed at 05 August 2021.
[5] William Fedus and Barret Zoph and Noam Shazeer. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961. 2021.
[6] Max Aliapoulios, Antonis Papasavva, Cameron Ballard, Emiliano De Cristofaro, Gianluca Stringhini, Savvas Zannettou, Jeremy Blackburn. The Gospel According to Q: Understanding the QAnon Conspiracy from the Perspective of Canonical Information. arXiv:2101.08750. 2021.
[7] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv:2103.14030. 2021.
[8] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin. Attention is All you Need. NIPS 2017 5998-6008.
[9] Pandu Nayak. Understanding searches better than ever before. Google The Keyword 2019. https://blog.google/products/search/search-language-understanding-bert/, accessed at 10 August 2021.
[10] Ambrish Rawat, Killian Levacher, Mathieu Sinn. The Devil is in the GAN: Defending Deep Generative Models Against Backdoor Attacks. arXiv:2108.01644. 2021.